[PaRev] On the Role of Attention Heads in Large Language Models Safety
Attention heads play a critical role in shaping both safe and harmful behaviors

이번에 리뷰해볼 논문은 Attention Head에 Safety Capability가 내재되어있음을 보이고, 이를 통해 LLM Safety에 대하여 연구한 논문이다.
ICLR 2025 On the Role of Attention Heads in Large Language Models Safety Zhenhond Zhou et al., Tongyi Lab, USTC, Tsinghua Univeristy, Nanyan Tech. Univeristy
1. Introduction
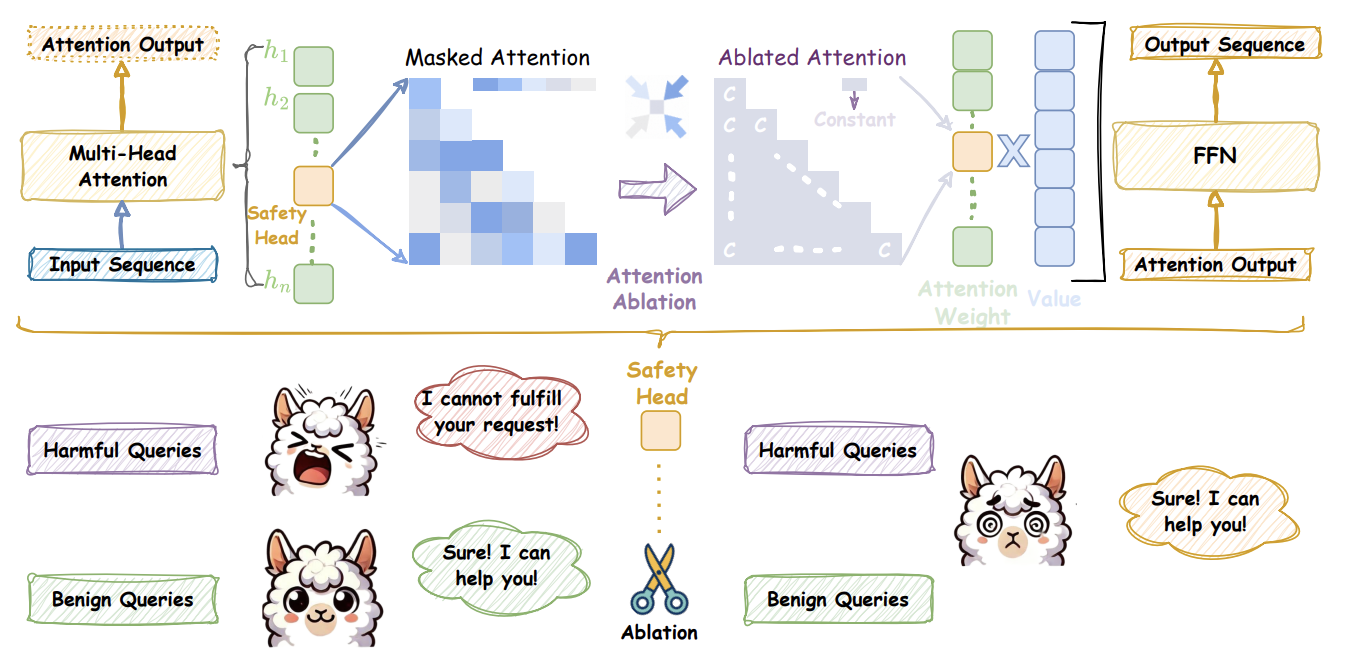 그림 1) On the Role of Attention Heads in Large Language Models Safety
그림 1) On the Role of Attention Heads in Large Language Models Safety
오늘날 LLM의 성능은 지속적으로 향상되고 있다. 하지만, LLM을 통한 보안 문제도 대두되고 있는데, 특히 언어 모델은 유해한 요청(harmful query)에 대해 안전하지 않고, 독성이 있는(toxic) 응답을 생성한다.
그래서 많은 LLM은 Alignment(Safe Guardrail 설정 등)로 이를 해결하고자 하지만, 공격자들은 Jailbreak로 가드레인을 우회하여 LLM에 대한 공격을 한다.
이에 따라, LLM에 대한 안전하고 윤리적인 개발을 위해 LLM의 내부 동작을 이해하는 것이 중요하다.
그러던 중, Mechanistic Interpretation이라는 개념이 등장했는데, 이는 인공지능 모델의 feature, neuron, layer, parameter 분석으로 해당 모델의 행동과 능력을 이해하려는 연구 분야를 의미한다.
이와 같은 연구 분야가 생겨나다보니, 보안 분야에서도 자연스럽게 Mutli-Head Attention에서 안전성 능력(Safety Capability)는 어떨지에 대해 의문을 갖게 되어 연구한 논문이 바로 이 논문이라고 생각된다.
본 연구의 목표는 아래와 같다.
GOAL: “Mutli-Head Attention에서 Safety Capability를 해석”
이를 위해 두 가지를 제안한다.
- 제안 1. Safety Head ImPortant Scores (Ships)
- Aligned mode에서 각 attention head가 safety (rejection behavior) 에 얼마나 기여하는 지를 정량적으로 측정하여 attribution(기여도를 수치화하여 귀속) 하기 위한 지표
- 제안 2. Safety Attention Head AttRibution Algorithm (Sahara)
- Ships를 기반으로 여러 attention head의 조합이 safety에 미치는 영향을 탐색, safety capability를 담당하는 head group을 식별하는 알고리즘
2. Preliminary
Large Language Models (LLM).
현재 대부분의 LLM 모델은 decoder-only 구조에 대부분 기반하고, 입력에 대해 다음 결과를 예측하는 ‘next token prediction’ 방식을 사용한다. LLM의 동작을 수식으로 나타내면, 입력 시퀀스 $x = x_1, x_2, \dots, x_s$에 대해 LLM은 다음 토큰의 확률 분포를 반환할 수 있다.
\[\begin{equation} p(x_{n+1} = v_i | x_1, \dots , x_s) = \frac{\exp(o_s \cdot W_{:,i})}{\sum^{|V|}_{j=1}\exp(o_s \cdot W_{:,j})} \end{equation}\]여기서 $o_s$는 마지막 잔여 문자열(residual stream)이고, $W$는 $o_s$를 vocabulary $V$의 각 토큰에 대응하는 logit으로 매핑하는 선형 함수이다. 이 확률 분포에서 sampling하면 새로운 토큰 $x_{n+1}$이 생성된다. 이 과정을 반복하면 결과 $R = x_{s+1}, x_{s+2}, \dots, x_{s+R}$을 얻을 수 있다.
Multi-Head Attention (MHA).
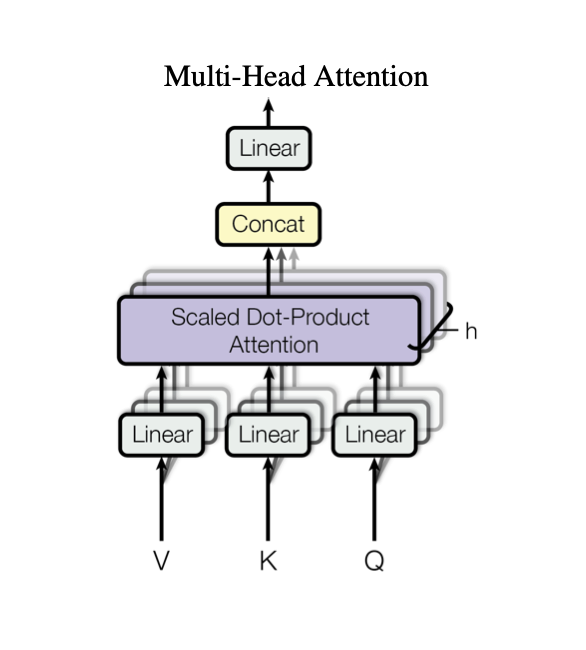 structure of Multi-Head Attention
structure of Multi-Head Attention
Multi-Head Attention의 각 head는 다양한 언어 작업에 따라 구별되도록 기여한다. 예를 들어, attention head가 $n$개라면,
\[\begin{align} \text{MHA}_{W_q, W_k, W_v} &= (h_1 \oplus h_2 \oplus \cdots \oplus h_n)W_o\\ h_i &= \text{Softmax}\left(\frac{W^i_qW^{iT}_k}{\sqrt{d_k/n}}\right) \end{align}\]이때, $\oplus$는 concatenation을 의미하고, $d_k$는 $W_k$의 dimension을 의미한다.
위 수식을 통해 Query, Key, Value 값에 기반하여 각 head의 결과를 합쳐서 하나의 출력으로 만든다. 즉, MHA는 어떤 데이터를 head의 개수에 따라 집중해서 보고(Attention), 그 정보를 추출해 합치는 역할을 수행한다.
LLM Safety and Jailbreak Attack.
LLM Safety를 위해서 alignment되도록 학습된 LLM은 아래와 같은 수식으로 표현된다. \(\begin{equation} \arg\min_\theta - \log p(R_\perp | x_\mathcal{H} = x_1, x_2, \dots, x_s ; \theta) \end{equation}\)
이때, $x_\mathcal{H}$은 harmful query이고, $R_\perp$는 ‘I cannot answer that’과 같은 거부 표현을 의미하며, $\theta$는 모델의 파라미터를 의미한다. 따라서, $-\log p(R_\perp | x_\mathcal{H})$ 를 최소화한다는 것은, 유해 질문에 대한 거부 응답 확률을 최대화하도록 학습한다는 것을 의미한다.
이렇게 aligned LLM을 대상으로 한 Jailbreak 공격은 아래와 같은 수식으로 표현할 수 있다.
\[\begin{equation} \text{maximize} \; p (D(R) = \text{True} \; | \; x_\mathcal{H} = x_1, x_2, \dots, x_s ; \theta) \end{equation}\]이때, $R$은 모델의 출력을 나타내고, $D(R)$은 safety discriminator(판별기)를 의미한다. $D(R)$의 결과가 True면 $R$이 유해함을 의미한다. 수식 (5)는 모델이 harmful response를 생성하도록 유도하는 수식이다.
본 논문에서는 “이 두 확률이 특정 attention head를 통해 조절할 수 있을 것이다!”를 보이고 싶은 것이다.
Safety Parameters.
Safety Parameter란, 이들이 수정되면 LLM의 Safety 관련 가드레일이 손상되어 비윤리적인 내용을 생성할 수 있는 parameter를 의미한다. 수식적으로 이를 정의하면 아래와 같다.
\[\begin{align} \Theta_{S,K} &= \text{Top-K}\{\theta_s : \arg\max_{\theta \in \Theta} \Delta p(\theta)\}, \\[6pt] \Delta p(\theta) &= \mathbb{D}_{\mathrm{KL}}\big( p(R_L \mid x_H; \theta_0) \;\|\; p(R_L \mid x_H; (\theta_0 \setminus \theta)) \big) \end{align}\]이때, $\theta_\mathcal{O}$는 원래 모델의 파라미터를 의미하고, $\theta_\mathcal{C}$는 후보 파라미터를 의미하며, $\backslash$는 특정 파라미터 $\theta_\mathcal{C}$의 제거(ablation)을 의미한다.
위 식의 목적은 harmful query $x_\mathcal{H}$를 거부할 확률을 가장 크게 감소시키는 $k$개의 parameter 집합 $\theta_\mathcal{S}$를 선택한다.
즉, LLM model의 safety는 특정 parameter에 의존하고, 본 연구에서는 이를 Safety Parameter라고 한다.
3. Safety Head ImPortant Score (Ships)
GOAL1: “특정 harmful query에 대한 Multi-head Attention 내부의 safety parameter를 식별”
Ships는 특정 attention head를 제거하여 해당 head의 safety capabilitiy를 측정하고, harmful query에 대한 출력 분포의 변화(KL divergence)를 기반으로 safety에 중요한 attention head를 식별한다.
3.1 Attention Head Ablation
기존 연구에서는 attention head ($h_i$)의 출력을 0으로 설정하는 방법으로 simple하게 head ablation을 수행한다.
하지만 $h_i$ 값을 0으로 만드는 방법은 해당 attention head의 출력값이 완전히 사라진다는 것만 알 수 있지, 어떤 기능이 제거되었는지 분해해서 해석할 수 없다.
이에 따라, 본 논문에서는 $Q$(Query)와 $K$(Key), 그리고 $V$(Value) 값을 조작함으로써 attention pattern과 output contribution을 분리하여 분석한다.
구체적으로, $h_i$ 값은 $W^i_q$, $W^i_k$, $W^i_v$ 값을 통해서 도출되는데, $W^i_q$와 $W^i_k$은 attention의 대상, $W^i_v$은 실제로 전달할 정보(content)를 나타낸다.
그렇기 때문에 $h_i$ 값을 0으로 만들면 attention pattern이 무너진 것인지($Q$/$K$), 아니면 계산된 결과가 전달되지 않은 것인지($V$) 구분할 수 없다.
또한, attention head는 redundancy를 가지기 때문에, 하나의 head를 제거($h_i$)를 제거하더라도, 다른 head가 이를 보완할 수 있다.
위와 같은 이유로, 본 논문은 attention head의 단순 제거가 아니라, 특정 기능을 선택적으로 약화시키는 방식으로 ablation을 수행하여 각 head의 역할을 보다 명확히 드러내고자 한다.
Undifferentiated Attention.
\[\begin{align} h^{mod}_i &= \text{Softmax}\left(\frac{\epsilon W^i_q W^{iT}_k}{\sqrt{d_k/n}}\right) W^i_v = A W^i_v, \end{align}\] \[\text{where} \;\; A = [a_{ij}] \;\;\; a_{ij} = \begin{cases} \frac{1}{i} & \text{if } i \ge j \\ 0 & \text{if } i < j \end{cases}\]Undifferentiated Attention 과정은 주의를 기울여 볼 부분을 없애는, 즉, 우선 모든 attention head들을 normalize하는 과정이다.
이는 $W_q$ 또는 $W_k$ Matrix를 scaling 함으로써 해당 head의 attention weight가 special matrix $A$로 붕괴(collapse)되는 과정을 활용하는데,
\[W^i_q \rightarrow \epsilon W^i_q \ \ \ \text{OR} \ \ \ W^i_k \rightarrow \epsilon W^i_k \ \ \ (\epsilon \ll 1)\]이때, $W_q$나 $W_k$를 수정하는 것은 동일한 효과를 가진다($\epsilon$ 을 어디에 곱해주어도 상관 없다).
\[\frac{\epsilon W^i_q W^{iT}_k}{\sqrt{d_k/n}} \approx 0\]그 결과 attention score는 0과 가까운, 입력에 관계없이 거의 동일한 분포로 수렴한다.
그리고 그 동일한 분포는 수식 (8)에서 언급한 special matrix $A$를 의미하는데, 위와 같은 하삼각 행렬(lower triangle matrix)이다.
이 단계를 통해 $Q$, $K$값, 즉, 어떤 정보를 선택하여 전달할 지에 대한 지표를 0으로 수렴하게 하여 정보 구별 능력을 망가뜨린다.
Scaling Contribution.
\[\begin{equation} h_i^{mod} = \text{Softmax}\left(\frac{W^i_qW^{iT}_k}{\sqrt{d_k/n}}\right) \epsilon W^i_v \end{equation}\]Scaling Contribution 과정은 어디에 attention할 지는 그대로 두고, 그 결과를 얼마나 전달할지만 조정하는 과정이다.
이 방법은 $W_v$에 $\epsilon$을 곱해 attention head의 출력을 조정한다.
\[W^i_v \ \rightarrow \ \epsilon W^i_v \ \ (\epsilon \ll 1)\]그러면 attention head 출력은
\[h^{mod}_i = \text{Softmax} \left( \frac{W^i_vW^{iT}_k}{\sqrt{d_k / n}} \right) \left( \epsilon W^i_v \right) = \epsilon h_i\]즉, attention weigh는 그대로 유지되고 head의 최종 출력만 scaling 된다.
3.2 Evaluate the Importance of Parameters for Specific Harmful Query
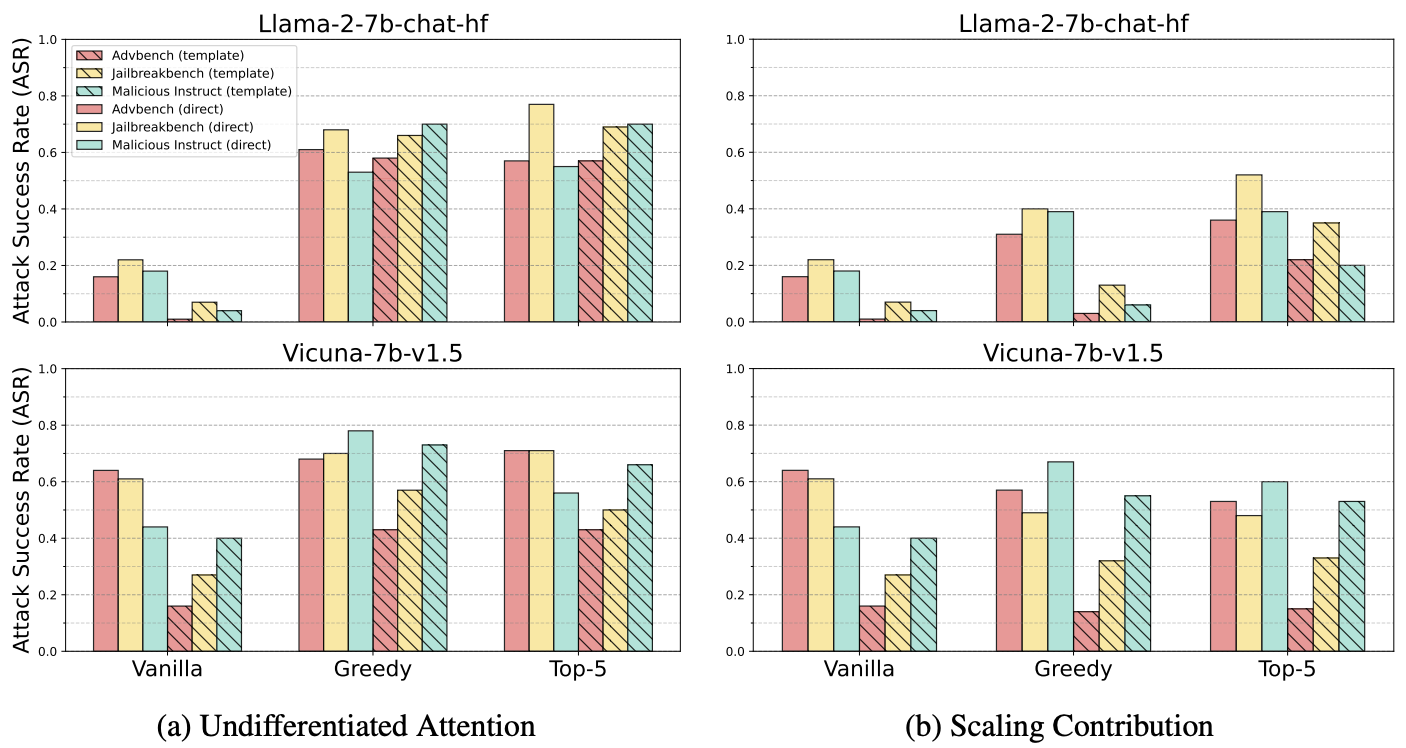 그림 2) 중요 safety attention 제거 이후의 harmful query들에 대한 ASR
그림 2) 중요 safety attention 제거 이후의 harmful query들에 대한 ASR
Aligned된 $L$개의 layer를 가진 모델$(\theta)$의 $l$ 번째 layer의 $i$ 번 attention head $h^l_i$를 Section 3.1에서 언급한 방법(Undifferentiated Attention, Scaling Contribution)으로 제거한다고 하자.
이때, 결과는 아래와 같은 새로운 확률분포를 따르게 된다.
\[p(\theta_{h^l_i}) = p(\theta_\mathcal{O} \ \backslash \ \theta_{h^l_i}), \;\; l \in (0, L)\]이 aligned 모델은 harmful query$(q_\mathcal{H})$에 대한 rejection 응답을 할 확률을 최대화하도록 학습된다.
이에 따라, Ships 는 아래와 같은 수식으로 정리할 수 있다.
수식에서 $\mathbb{D}_\text{KL}$은 Kullback-Leibler 분산을 의미한다.
이전 연구들에 따르면, 다양한 harmful query 들에 대해서 rejection 응답은 꽤나 일관적이라는 것을 알 수 있다.
게다가, 현재 많이 사용되는 언어모델은 일부 attention head를 제거해도 그와 중복된 역할을 하는 head가 있어 전체적인 성능에 거의 영향을 주지 않는다는 특성(attention redundancy)이 있다.
따라서, 특정 attention head의 기능을 약화시켰을 때 rejection 응답의 비율이 줄어든다면, 이는 제거된 head가 safety parameter일 가능성이 높음을 시사한다.
3.3 Ablate Attention Heads for Specific Query Impact Safety
이번 Section에서는 Ships의 효과를 검증하기 위해 Llama-2-7b-chat과 Vicuna-7b-v1.5 모델을 대상으로 Advbench, Jailbreakbench, Malicious Instruct 데이터셋을 활용하여 실험을 진행한다.
실험은 3단계로 진행되는데,
- harmful query$(q_\mathcal{H})$에 대해서
Ships로 safety head를 선택한다. - head ablation을 수행한다.
- 각 query마다 128개의 token을 생성한다.
- 그 결과로 safety 변화를 측정한다.
이 실험은 Greedy Sampling과 Top-k sampling를 사용한다.
- Greedy Sampling: 결과 재현성(Reproducibility) 확보
- Top-k Sampling: 확률 분포 상 변화 관찰
이때, Safety Capability의 변화를 평가하는 방법은 Attack Success Rate의 변화로 평가하게 된다.
\[\begin{equation} \text{ASR} = \frac{1}{|Q_\mathcal{H}|} \sum_{x^i \in Q_\mathcal{H}} [ D(x_{n+1} : x_{n+R} \ | \ x^i ) = \text{True}] \end{equation}\]수식에서 $Q_\mathcal{H}$은 harmful query dataset을 의미한다.
실험 결과로 Ships로 식별된 가장 중요한 safety head(전체 parameter 중 0.006%)를 제거하면 ASR이 크게 증가함을 알 수 있다.
Llama-2-7b-chat: 0.04에서 0.64로 16배 증가Vicuna-7b-v1.5: 0.27에서 0.55로 2배 증가
이는 특정 attention head가 모델의 safety capability에 핵심적인 역할을 수행함을 보인다.
4. Safety Attention Head AttRibution Algorithm (Sahara)
AIM 2: “
Ships를 데이터셋 수준의 적용으로 확장하여, 다양한 query에 대해 일관되게 safety capability를 가지는 attention head를 식별한다.”
Sahara는 Ships를 활용하여 safety 능력에 결정적인 attention head를 특정하는 접근법이다.
4.1 Generalize the Impact of Safety Head Ablation
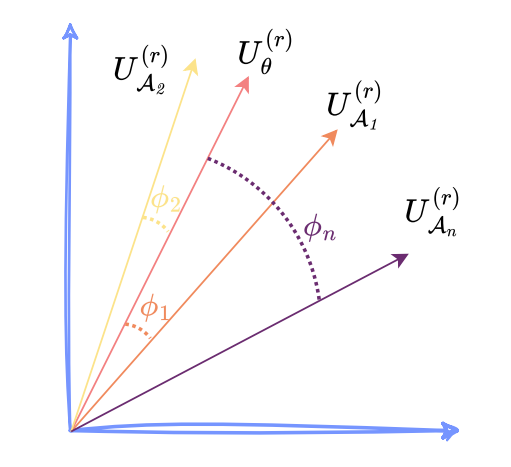 그림 3) 일반화된
그림 3) 일반화된 Ships 표현
이번 Section에서는 전체 데이터셋 수준에서 Safety Head를 망가뜨렸을 때의 영향을 측정한다.
이를 위해 $a$로 표현되는 ‘residual stream activation’에 대한 기존 연구를 참고하는데, 해당 activation가 safety 관련 feature를 포함함을 전제로 한다.
위와 같은 아이디어에 기반하여 특이값 분해 $($Singular Value Decomposition, $\text{SVD})$ 을 적용하여 safety-critical 한 feature들을 식별하는 것이 이번 Section의 목표이다.
과정은 다음과 같다.
- harmful query dataset $Q_\mathcal{H}$를 모델에 입력
- 각 query에 대한 top layer residual activation $a$ 수집
- 이를 쌓아 matrix $M$ 구성 $(M = [a_1, a_2, \dots, a_n])$
그리고 $M$에 대하여 SVD를 적용한다.
\[\text{SVD}(M) = U \Sigma V^T\]이때, $U$는 representation 공간에서의 주요 feature 방향을 나타낸다.
만약 입력 데이터셋이 harmful할 경우, $U$는 harmful query 전체에 공통적으로 나타나는 safety-related representation 구조를 나타내게 된다.
Safety Capability를 가지는 attention head를 특정하기 위해서 두 가지 Matrix를 비교한다.
$U_\theta$: Aligned model에서의 representation ($U_\theta \in \mathbb{R}^{ Q_\mathcal{H} \times d_k}$) - $U_\mathcal{A}$: 특정 attention head를 ablation한 model에서의 representation
Ablation의 영향력을 정량화하기 위해서, $U_\theta$와 $U_\mathcal{A}$ 사이의 principle angle을 계산한다.
Ships를 dataset 수준으로 일반화한 결과는 $\phi$로 표현되며, 전체 수식은 아래와 같다.
이때 앞쪽 $r$개 차원은 SVD에서 가장 중요한 feature를 포함하고, 본 연구에서는 이에 주목한다.
$\sigma_r$은 $r$번째 특이값(singular value)를 의미하고, $\phi_r$은 $U_\theta^{(r)}$과 $U_\mathcal{A}^{(r)}$ 사이의 principle angle을 의미한다.
4.2 Safety Attention Head AttRibution Algorithm
이번 Section에서는 Sahara를 본격적으로 소개한다.
Section 4.1에서는 dataset 수준에서 attention head를 망가뜨리는 것의 safety 측면에서의 효과를 평가하기 위한 Ships의 일반화된 버전을 설명했다.
하지만, 기존 연구에 따르면, LLM를 구성하는 요소(components)들은 서로 상호작용하며 작동한다고 한다.
이 연구를 통해 충분히 safety capability도 여러개의 attention head들의 협력으로 만들어지는 것은 아닌지 의문을 가질 수 있고, 본 연구에서는 이와 같은 가설에 기반하여 Sahara를 고안한다.
GOAL2: “여러 attention head가 함께 작동하는 Safety Head 그룹 식별”
 Algorithm) Safety Attention Head AttRibution Algorithm (
Algorithm) Safety Attention Head AttRibution Algorithm (Sahara)
Sahara의 입력은 다음과 같다.- $Q_\mathcal{H}$: harmful query dataset
- $\theta_\mathcal{O}$: Aligned Model의 parameter
- $\mathbb{L}$: Layer 수
- $\mathbb{N}$: attention head 수
- $\mathbb{S}$: 찾을 head 개수 (보통 5 이하)
- $G$: 중요한 attention head 집합
- 각 Layer와 attention head들을 쭉 순회하면서
- $l$ 번째 layer의 $i$ 번째 attention head $(h^l_i)$ 와 $G$를 포함한 집합 $T$를 만들고
- 기존 model $\theta_\mathcal{O}$ 에서 집합 $T$ 를 ablation 한 상태에서
Ships를 계산한다. - 그리고 모든 후보의 score를 기록 $(\text{Scoreboard}_\text{s})$한 후,
- 그 중에서 가장 높은 score를 기록한 head를 추가한다.
4.3 How Does Safety Heads Affect Safety?
Ablating Heads Results in Safety Degradation.
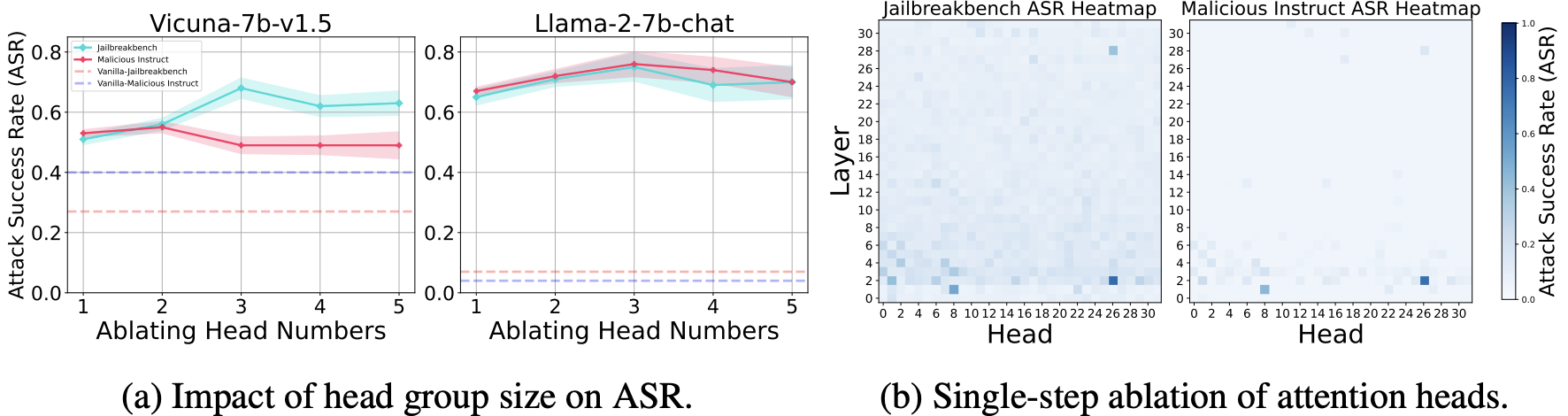 그림 4) head 제거와 model safety 사이의 상관관계 (
그림 4) head 제거와 model safety 사이의 상관관계 (new token=128, k=5 for top-k sampling)
그림 4(a)는 두 가지 모델 모두에서 Sahara를 통해 safety score가 높은 attention head를 제거했을 때, ASR이 확연히 증가한 것을 확인할 수 있었다.
그림 4(b)는 마찬가지로 두 모델에서 head를 개별적으로 제거했을 때 ASR 변화를 heatmap으로 표시한 그림이다.
대부분의 head는 제거해도 ASR의 변화와 무관하지만, 특정 head를 제거했을 때는 ASR이 크게 증가한 것을 확인할 수 있다.
이는 safety capability가 특정 attention head에 집중되어 있다는 본 연구의 주장을 뒷받침한다.
Impact of Head Group Size.
위 그림 4(a)에서 보면, 일반적으로 ablate 하는 head의 개수가 3일 때까지 ASR가 증가하는 것을 볼 수 있다.
이후 연구에서 밝혀진 내용인데, attention head의 ablation을 많이 하면 model의 출력이 망가져서 ASR 평가 자체가 어려워진다는 것이 드러났다.
Safety Heads are Sparse.
그림 4(b)에서도 알 수 있듯, Safety attention head는 모델 전체에 고르게 퍼져있지 않다.
이는 아주 소수의 attention head가 safety 에 치명적이며, 대부분은 safety에 대해 무시할 수 있는 수준의 영향을 준다는 것이다.
Our Method Localizes Safety Parameters at a Finer Granularity.
| Method | Parameter Modification | ASR | Attribution Level |
|---|---|---|---|
| ActSVD | ~5% | 0.73 ± 0.03 | Rank |
| GTAC&DAP | ~5% | 0.64 ± 0.03 | Neuron |
| LSP | ~3% | 0.58 ± 0.04 | Layer |
| Ours | ~0.018% | 0.72 ± 0.05 | Head |
ActSVD, Generation-Time Activation Contrasting & Dynamic Activation Patching (GTAC & DAP), Layer-Specific Pruning (LSP) 와 같이 기존의 Mechanistic Interpretability를 활용하는 연구와 비교하면 위 표와 같다.
본 연구에서 제안한 기법을 사용하면 굉장히 소수(0.018%, attention head 3개)의 parameter를 수정함으로써, 큰 ASR의 변화가 나타남을 확인하였다.
Our Method is Highly Efficient.
| Method | Full Generation | GPU Hours |
|---|---|---|
| Masking Head | ✓ | ~850 |
| ACDC | ✓ | ~850 |
| Ours | ✗ | 6 |
attention head의 중요도를 평가하는 방법은 크게 두 가지 방법으로 나뉜다.
1. 전체 텍스트 생성 후 Bilingual Evaluation Understudy Score(BLEU)와 같은 응답 기반 지표의 변화를 측정하는 방식
2. Indirect Object Identification (IOI) 와 같이 single forward pass로 평가할 수 있는 특수 task를 사용하는 방식
그리고 model의 safety를 평가하는 경우 기존 연구에서는 toxicity 혹은 harmful 여부를 판단할 때 full text generation(128개 token) 실험이 필수적이다.
하지만, 본 연구에서 제시한 방법에 따르면, 응답 자체를 생성하는 과정 없이 attention head ablation 전후의 내부 representation 변화를 기반으로 head의 safety capability 측면에서의 중요도를 평가한다.
이에 따라, computational cost를 크게 줄일 수 있다.
5. An In-Depth Analysis for Safety Attention Heads
Section 5에서는 Safety Attention Head에 대한 기능을 더욱 깊게 분석한다.
5.1 Different Impact between Attention Weight and Attention Output
Question 1. “Attention 대상과, Attention 출력 정도 중, 어떤 것이 더 영향력이 클까?”
Section 3.1에서 LLM safety capability에 영향을 주는 Undifferentiated Attention과 Scaling Contribution 에 대해서 언급하였다.
여기서 주목할 점은, 각 attention head에서 Query$(W_q)$, Key$(W_k)$, Value$(W_v)$ matrix들의 변경이 model safety에 어떤 중요성이 있는지 하는 것이다.
Safety Head Can Extracting Crucial Safety Information.
| Method | Dataset | 1 | 2 | 3 | 4 | 5 | Mean |
|---|---|---|---|---|---|---|---|
| Undifferentiated Attention | Malicious Instruct | +0.63 | +0.68 | +0.72 | +0.70 | +0.66 | +0.68 |
| Undifferentiated Attention | Jailbreakbench | +0.58 | +0.65 | +0.68 | +0.62 | +0.63 | +0.63 |
| Scaling Contribution | Malicious Instruct | +0.01 | +0.02 | +0.02 | +0.01 | +0.03 | +0.02 |
| Scaling Contribution | Jailbreakbench | −0.01 | +0.00 | −0.01 | +0.00 | +0.00 | +0.00 |
| Undifferentiated Attention | Malicious Instruct | +0.66 | +0.28 | +0.33 | +0.48 | +0.56 | +0.46 |
| Undifferentiated Attention | Jailbreakbench | +0.62 | +0.46 | +0.39 | +0.52 | +0.52 | +0.50 |
| Scaling Contribution | Malicious Instruct | +0.07 | +0.20 | +0.32 | +0.24 | +0.28 | +0.22 |
| Scaling Contribution | Jailbreakbench | +0.03 | +0.18 | +0.41 | +0.45 | +0.44 | +0.30 |
이를 위해 수식 (8)로 표현되는 Undifferentiated Attention, 그리고 수식 (9)로 표현되는 Scaling Contribution의 영향을 표로 정리하면 위와 같다.
표의 위쪽 4행은 Sahara를 사용하여 ASR을 높인 상태이고, 아래 4행은 특정 harmful query의 효과에 집중한다.
실험 결과를 해석해보면, Undifferentiated Attenton은 확연하게 safety capability를 줄인다.
반대로, Scaling Contribution에서의 결과는 dataset 수준에서는 효과가 미미한 것에 비해, 특정 harmful query에서의 결과는 확연한 것을 보여준다.
이러한 결과는 attention 기반 safety가 단순한 정보 전달이 아닌, 입력에서 중요한 정보를 선택적으로 추출하는 과정에서 형성된다는 점을 시사한다.
특히, 평균적인 attention 분포는 malicious feature를 제대로 포착하지 못해 오탐(false positive)을 유발할 수 있다.
또한, LLM의 parameter redundany로 인해, 특정 head를 제거해도 다른 head에 의해 보완되어 일부 safety head의 경우 실제보다 score가 낮게 평가될 가능성이 있다.
Attention Weight and Attention Output Do Not Transfer
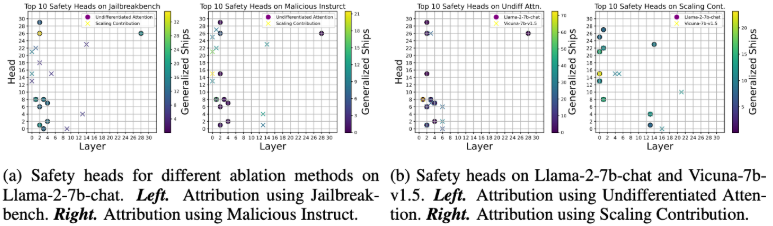 그림 5) 일반화된
그림 5) 일반화된 Ships를 사용하여 계산된 Safety 능력 상위 10개
그림 5(a)에서 보이는 것처럼, Ships 점수가 높은 상위 10개 safety head를 비교해봤을 때, 겹치는 지점이 별로 없고, Undifferentiated Attention으로 식별된 head가 Scaling Contribution으로 식별된 head보다 일관성이 있었다.
이를 통해,
- 서로 다른 attention head가 safety에 서로 다른 영향을 미칠뿐만 아니라,
- Undifferentiated Attention으로 식별된 head가 중요한 정보를 추출하는 데 핵심적이다.
라는 것을 알 수 있다.
5.2 Pre-training is Important for LLM Safety
Question 2. “LLM의 Safety Capability는 alignment가 더 중요할까, pre-training이 더 중요할까?”
Section 5.2에서는 이전 연구들에서 언급했던, LLM Safety에 대해서 model의 alignment 과정도 중요하지만, base model 자체의 역할도 중요하다는 점에 대해서 실험을 진행한다.
그림 5(b)를 통해서 어떤 ablation 방법을 사용하든 두 model 간의 safety head가 많이 겹친다는 것을 알 수 있다.
이는 model의 pre-training 과정이 safety capability 형성에 큰 영향을 미친다는 점을 시사한다.
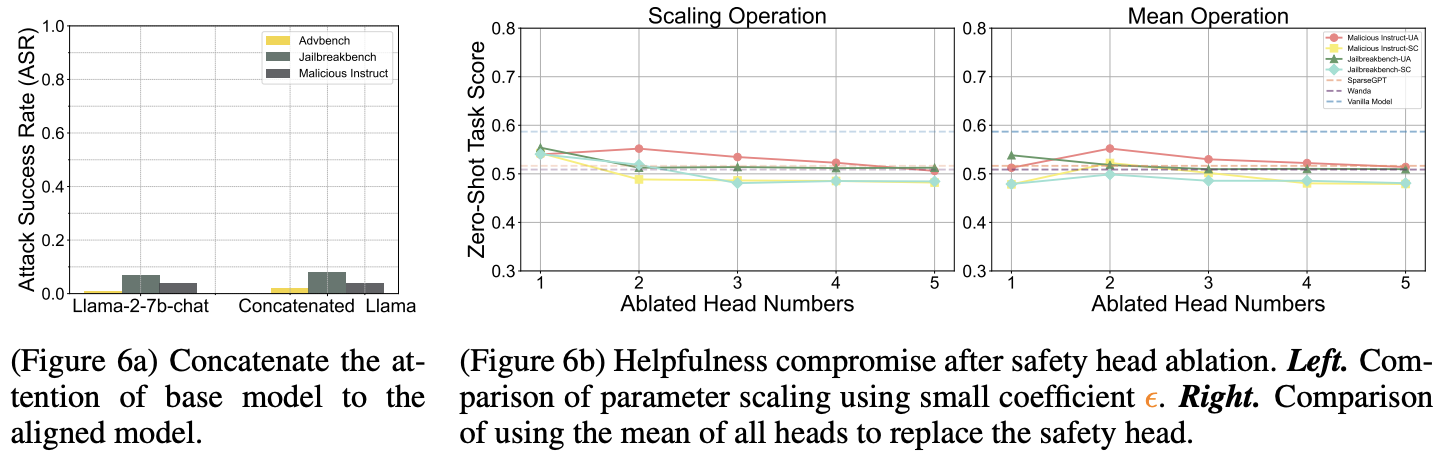 그림 6) safety parameter/attention head에 대한 고찰
그림 6) safety parameter/attention head에 대한 고찰
attention head와 pre-training 단계의 safety에 있어 상관 관계를 알아보기 위해, 본 실험에서는 attention parameter를 pre-training 단계의 base model에서 가져오고, 나머지 parameter는 aligned된 model의 값을 유지한 혼합 모델을 구성하였다.
- Attention Parameter
- Query: $W_q$
- Key: $W_k$
- Value: $W_v$
- The other Parameter
- Feed Forward
- Add & Norm
- Embedding
- Positional Encoding
- Output Projection
그림 6(a)를 보면, 그 결과 해당 모델은 aligned model과 유사한 수준의 safety capability를 유지하는 것으로 나타났다.
이는 attention mechanism의 safety 기능이 alignment 과정에서 학습되는 것이 아니라, pre-training 단계를 통해 형성되는 것임을 시사한다.
5.3 Helpful-Harmless Trade-off
Question. “Safety head가 safety만을 담당하는가, 아니면 다른 능력에도 영향을 주는가?”
LLM의 뉴런은 ‘superposition’, ‘polysemanticity’라는 특성이 있는데, 이는 여러 기능을 동시에 가질 수 있다는 것을 의미한다.
이는 곧, safety head가 다른 기능에도 영향을 줄 가능성이 있다.
이를 검증하기 위해, safety head를 제거한 후 모델의 일반 성능(helpfulness)을 평가하였다.
실험 결과, safety head를 제거하면 safety capability는 크게 감소하지만, BoolQ, RTE 등 다양한 zero-shot task에서의 성능은 거의 유지되는 것으로 나타났다.
이는 safety head가 주로 safety 기능을 담당하며, 일반적인 문제 해결 능력과는 비교적 독립적으로 작동함을 의미한다.
또한, SparseGPT 및 Wanda와 같은 pruning 방법과 비교했을 때, 본 방법은 더 적은 성능 손실을 보이며, 특히 Undifferentiated Attention 방식이 높은 성능 유지율을 보였다.
이는 제안된 ablation 방법이 효율적으로 safety만을 조작할 수 있음을 보여준다.
6. Conclusion
이 논문에서는 LLM에서 attention head의 safety capability 능력을 해석하기 위한 방법인 Safety Head ImPortant Scores(Ships)를 제안한다.
또한, Ships를 데이터셋 수준으로 일반화하여 Safety Capability를 약화시키는 head 그룹을 식별하는 Safety Attention Head AttRibution Algorithm(Sahara)을 제안한다.
또한, 제안에 대한 실험 결과는 몇 가지 중요한 insight들을 보여준다.
- 특정 attention head는 safety에 핵심적이고,
- 미세 조정된 모델 간의 safety head는 겹치는 부분이 있으며,
- 이러한 head를 제거해도 모델의 기능에는 거의 영향을 미치지 않는다.