[PaRev] NDAD: Negative-Direction Aware Decoding for Large Language Models via Controllable Hallucination Signal Injection
A review of NDAD, a training-free decoding method that suppresses hallucination by constructing and subtracting controllable hallucination signals.
On May 8, 2026, I reviewed NDAD: Negative-Direction Aware Decoding for Large Language Models via Controllable Hallucination Signal Injection.
[ ICLR 2026 ] NDAD: Negative-Direction Aware Decoding for Large Language Models via Controllable Hallucination Signal Injection
Panjia Qiu, Mingyuan Fan, Cen Chen, Daixin Wang
The paper proposes a training-free decoding method for improving factual reliability in large language models. Its central idea is simple but interesting: instead of only trying to amplify factual signals, NDAD intentionally induces hallucination-leaning signals, treats them as a negative direction, and adjusts the final logits away from that direction.
All figures and tables in this post are taken from my seminar slide deck, which included figures and tables from the original paper. I did not generate any synthetic figures.
1. Background: Hallucination Mitigation
LLM hallucination mitigation methods can roughly be grouped into several families.
| Category | Typical idea |
|---|---|
| Retrieval-based methods | Bring in external knowledge through RAG or retrieval-augmented verification. |
| Training- and preference-based methods | Change model behavior through SFT, RLHF, DPO, or related preference optimization methods. |
| Self-evaluation-based methods | Ask the model to critique, resample, or compare multiple reasoning paths. |
| Intervention decoding methods | Modify the decoding process without retraining the model. |
NDAD belongs to the last category. This makes it attractive because it does not require model retraining or an external knowledge base. It operates at inference time by modifying the output distribution.
Prior intervention decoding methods such as DoLa and SLED use internal model representations to improve factuality. A common pattern is to compare early-layer and final-layer signals, then use the contrast to steer generation. NDAD takes a different direction. It tries to explicitly construct a hallucination signal and then suppress it.
In other words, the mindset changes from:
“Find a better factual direction and move toward it.”
to:
“Find the hallucination direction and move away from it.”
That is the main reason I found this paper worth reviewing.
2. Autoregressive Decoding Setup
An autoregressive language model predicts the next token from an input prefix. If the prefix before time step $t$ is:
\[x_{<t} = \{x_1, x_2, \dots, x_{t-1}\}\]the model converts the tokens into hidden states and passes them through $L$ transformer layers. For each layer $l$, the hidden state can be projected into logits:
\[logits_l^{[t]} = \psi(h_l^{[t]})\]and a token distribution:
\[P_l^{[t]} = softmax(logits_l^{[t]}), \quad l = 1, \dots, L\]In ordinary decoding, the final-layer logits $logits_L$ are used to choose the next token. NDAD keeps this basic decoding structure, but it adds a correction term before token selection.
3. Overview of NDAD
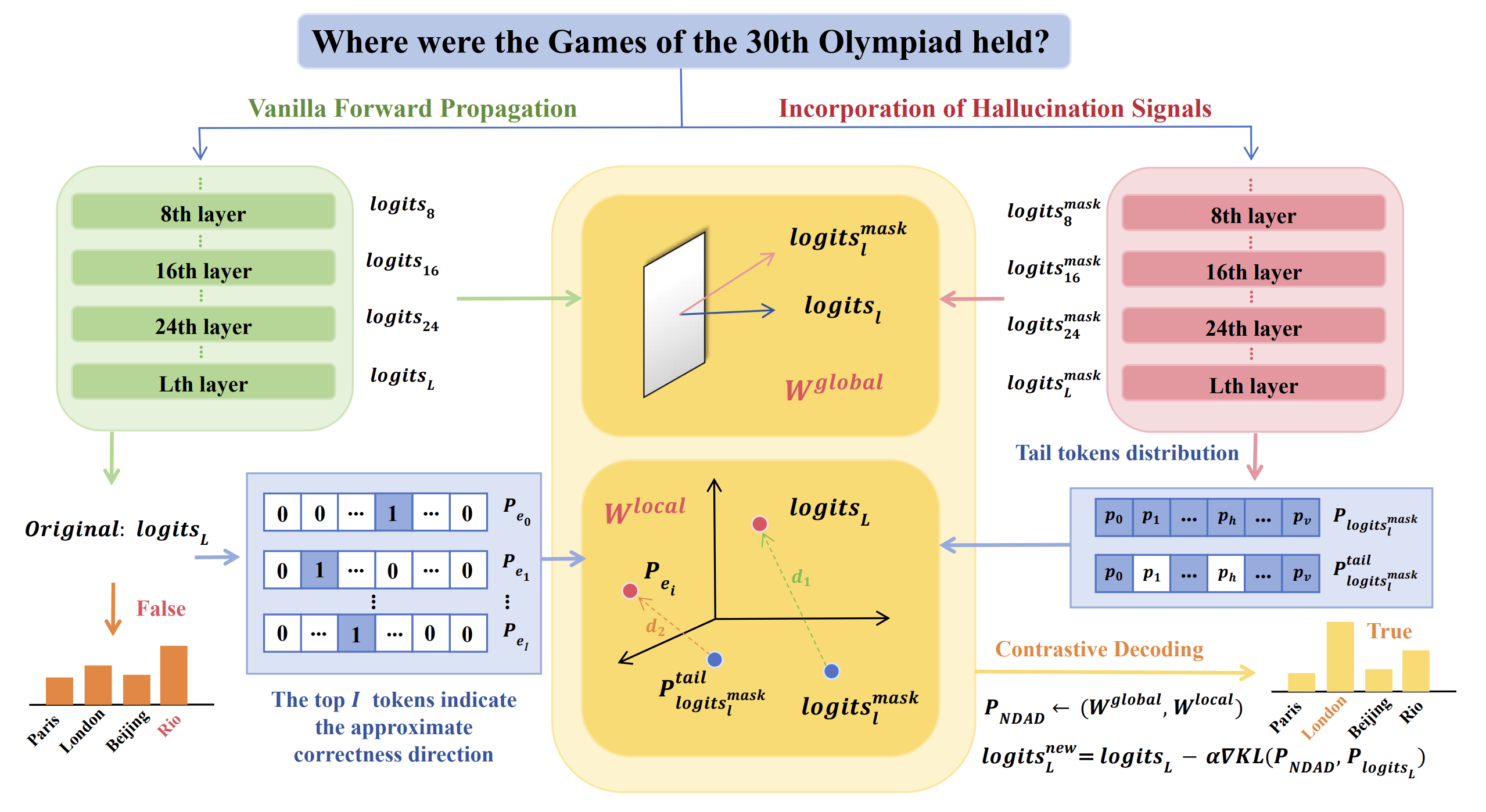 Figure 1. Overview of NDAD.
Figure 1. Overview of NDAD.
The whole NDAD pipeline can be read as three stages.
- Generate hallucination signals. Select important attention heads, mask them, and observe the logits produced by the weakened model path.
- Weight the signals. Use global consistency and local divergence to decide how much each hallucination signal should influence decoding.
- Apply negative-direction aware decoding. Aggregate the weighted signals into a latent hallucination distribution and adjust the final logits away from it.
The phrase “hallucination signal” can sound strange at first. In this paper, it means a distribution that appears when factuality-preserving internal components are weakened. If masking certain attention heads makes the model less factual, then the resulting distribution can reveal the direction in which hallucination-prone generation would move.
NDAD then uses that direction as something to repel from.
4. Hallucination Signal Generation
NDAD starts from the assumption that some attention heads play an important role in preserving factuality. This assumption is influenced by prior work on retrieval heads, especially the idea that some attention heads retrieve or stabilize factual information in long-context settings.
For each transformer layer $l$, NDAD obtains an importance score for each attention head:
\[\{s_{l,1}, s_{l,2}, \dots, s_{l,n}\}\]The scores are normalized into a probability distribution:
\[p_{l,i} = \frac{s_{l,i}}{\sum_{j=1}^{n} s_{l,j}}\]Then the entropy of the layer is computed:
\[E_l = - \sum_{i=1}^{n} p_{l,i} \log p_{l,i}\]The interpretation is important:
- If $E_l$ is high, importance is spread across many heads.
- If $E_l$ is low, importance is concentrated in a small number of heads.
NDAD selects the layers with low entropy, then masks the top-$X$ important heads in those layers. This produces masked logits:
\[logits_l^{mask}\]These masked logits are treated as hallucination-oriented signals.
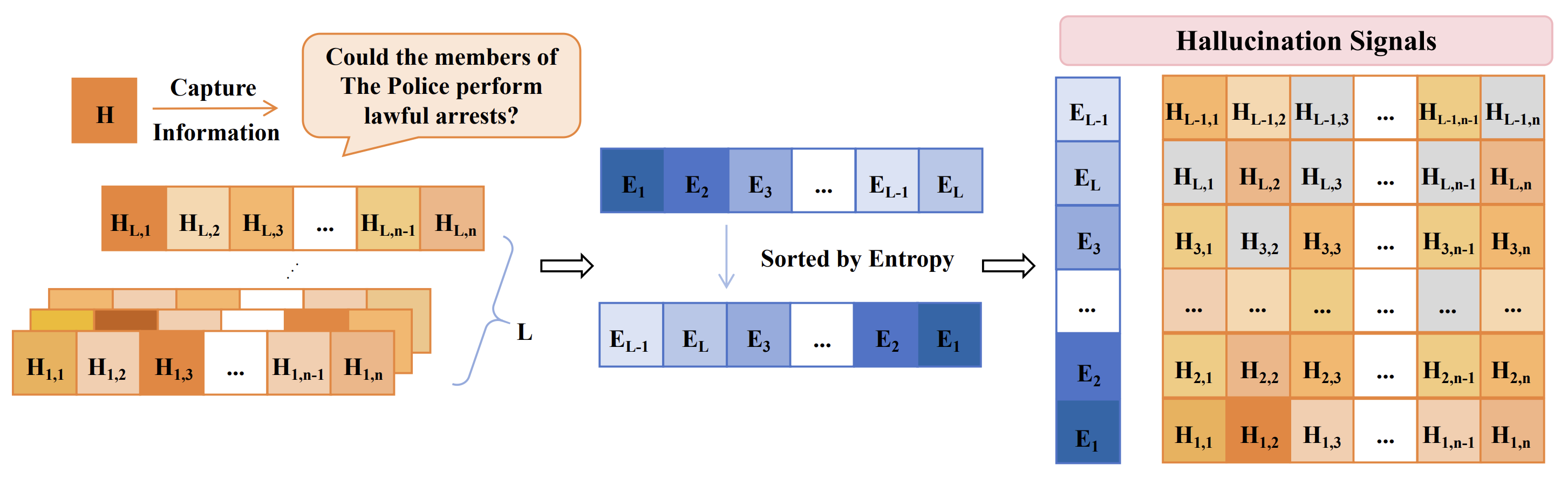 Figure 2. Hallucination signal generation through attention-head masking.
Figure 2. Hallucination signal generation through attention-head masking.
The intuition is that if the model depends on specific heads for factual generation, then masking those heads should expose a weaker, less factual, or more unstable generation trajectory. NDAD does not directly decode from that trajectory. Instead, it uses the trajectory as a negative reference.
The paper also provides the algorithmic workflow for hallucination signal induction.
 Algorithm 1. Hallucination signal induction.
Algorithm 1. Hallucination signal induction.
This part of the paper is conceptually clean: first identify influential heads, then damage them in a controlled way, then observe where the model tends to go.
However, as I will discuss later, the experiments also raise a question: if random head or layer masking sometimes performs similarly to the proposed importance-guided masking, how essential is the head-importance hypothesis?
5. Dynamic Weighting: Global and Local Perspectives
Once hallucination signals are generated, NDAD needs to decide how much each signal should matter. The paper introduces two complementary weights.
5.1 Global Consistency
Global consistency measures whether the hallucination signal from a layer is directionally related to the original logits from that same layer.
\[W_l^{global} = \phi(c_l)\]where:
\[c_l = cos\_sim(logits_l, logits_l^{mask})\]and $\phi(\cdot)$ maps the value into $[0, 1]$.
My interpretation is that the global weight estimates the reliability of the masked signal. If the masked logits are still directionally meaningful with respect to the original layer logits, then the hallucination signal is treated as more useful.
This does not mean the masked distribution is factual. It means the signal is relevant enough to be used as a reference for what should be suppressed.
5.2 Local Divergence
Local divergence is more token-specific. It asks whether low-probability tokens in the masked distribution are likely to evolve toward the mature final output.
NDAD approximates the final-layer distribution as the mature distribution. It then selects the top-$I$ tokens from the final distribution and constructs one-hot candidate distributions:
\[\mathcal{T} = \{P_{e_1}, P_{e_2}, \dots, P_{e_I}\}\]At the same time, NDAD removes the top-$I$ tokens from the masked distribution, leaving a tail distribution:
\[P_{logits_l^{mask}}^{tail}\]This tail distribution is important because low-probability tokens are often associated with reduced factuality. The local weight compares two directions:
- the direction from the masked logits to the final logits
- the direction from the tail hallucination distribution to a candidate mature token distribution
If those directions are similar, the token is considered risky because a low-quality tail signal may evolve toward the final output. NDAD assigns a larger local weight so that this trajectory can be suppressed.
In my reading, the local weight is the more operationally important component. The global weight asks whether the masked signal is usable at the layer level, while the local weight asks which token-level directions are dangerous.
The final weight combines both:
\[W_{l,i} = W_l^{global} W_{l,i}^{local}\]Then NDAD squares the weight:
\[\tilde{W}_{l,i} = (W_{l,i})^2\]This gives stronger influence to high-confidence negative directions and reduces the impact of weak or noisy ones.
6. Negative-Direction Aware Decoding
After computing the weights, NDAD builds a latent hallucination distribution.
First, it normalizes the squared weights within each layer:
\[P_l = \frac{(\tilde{W}_{l,1}, \tilde{W}_{l,2}, \dots, \tilde{W}_{l,I})}{Z_l}\]where:
\[Z_l = \sum_{i=1}^{I}\tilde{W}_{l,i}\]Then it aggregates across layers:
\[P_{NDAD} = \sum_{l=1}^{L} N_l P_l\]where:
\[N_l = \frac{Z_l}{\sum_{l=1}^{L} Z_l}\]The final decoding update is:
\[logits_L^{new} = logits_L - \alpha \nabla KL(P_{NDAD}, P_{logits_L})\]Here, $\alpha$ is the evolution rate. The update subtracts probability mass from hallucination-prone directions while trying to preserve high-confidence predictions.
 Algorithm 2. Negative-Direction Aware Decoding.
Algorithm 2. Negative-Direction Aware Decoding.
This is why NDAD is still a decoding method rather than a training method. It does not change model parameters. It changes how the final logits are used at inference time.
7. Experiments
The paper evaluates NDAD across several benchmark types.
| Benchmark type | Datasets |
|---|---|
| Short-answer factuality | TruthfulQA |
| Long-context factuality | FACTOR-Wiki |
| Chain-of-thought reasoning | StrategyQA, GSM8K |
| Open-ended generation | TriviaQA, PopQA, NQ-Open |
The baselines include Greedy Decoding, DoLa-low, DoLa-high, AD, and SLED.
7.1 Llama model results
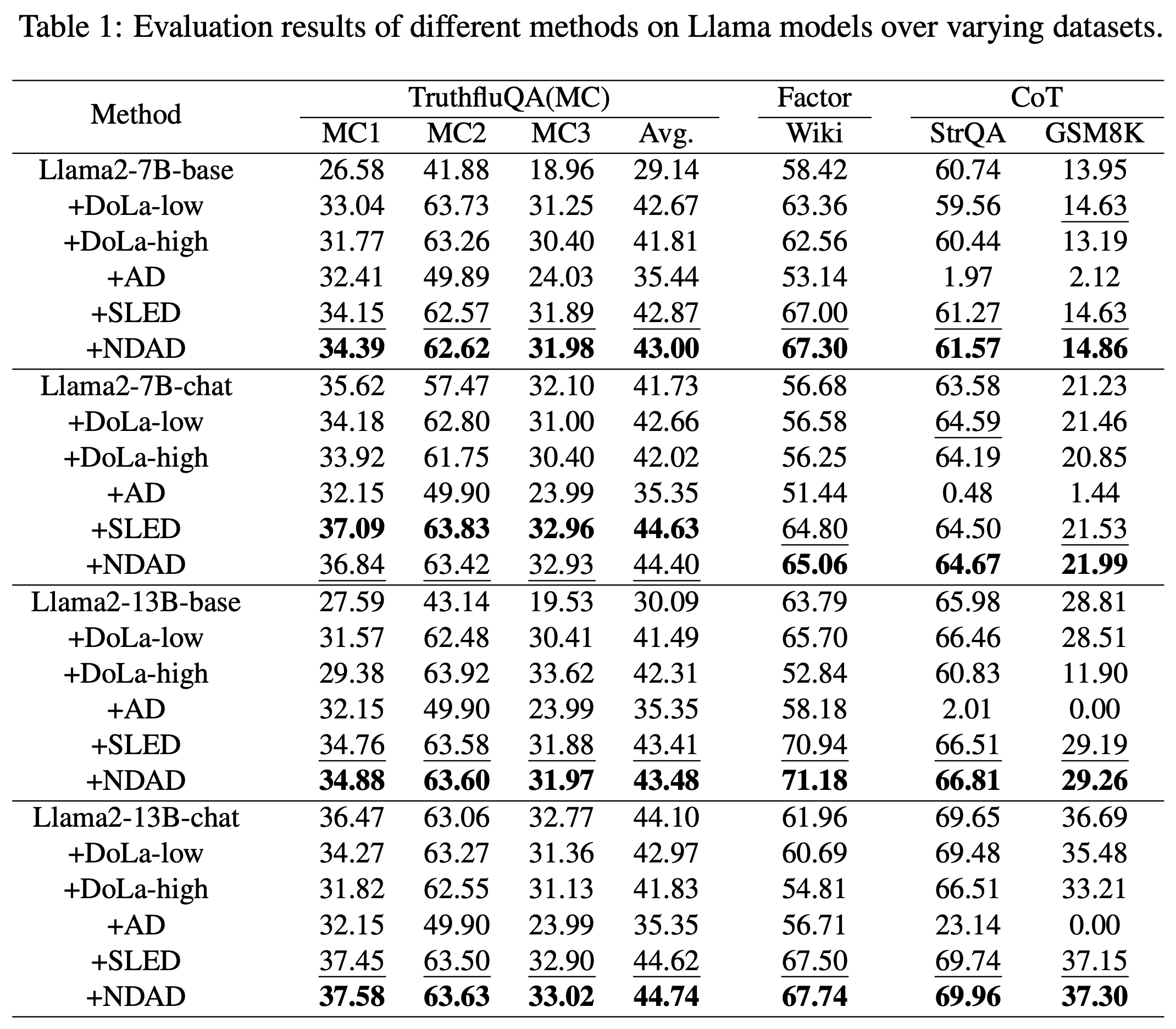 Table 1. Evaluation results on Llama models across several datasets.
Table 1. Evaluation results on Llama models across several datasets.
The main Llama results show that NDAD is generally competitive with or slightly better than SLED. The gains are not always large, but they are consistent across many of the reported settings.
The strongest point is robustness. AD is unstable in several settings, especially on reasoning tasks. SLED is a strong baseline, but NDAD tends to improve the final scores by using hallucination signals directly rather than only relying on early-layer contrast.
7.2 Open-ended generation
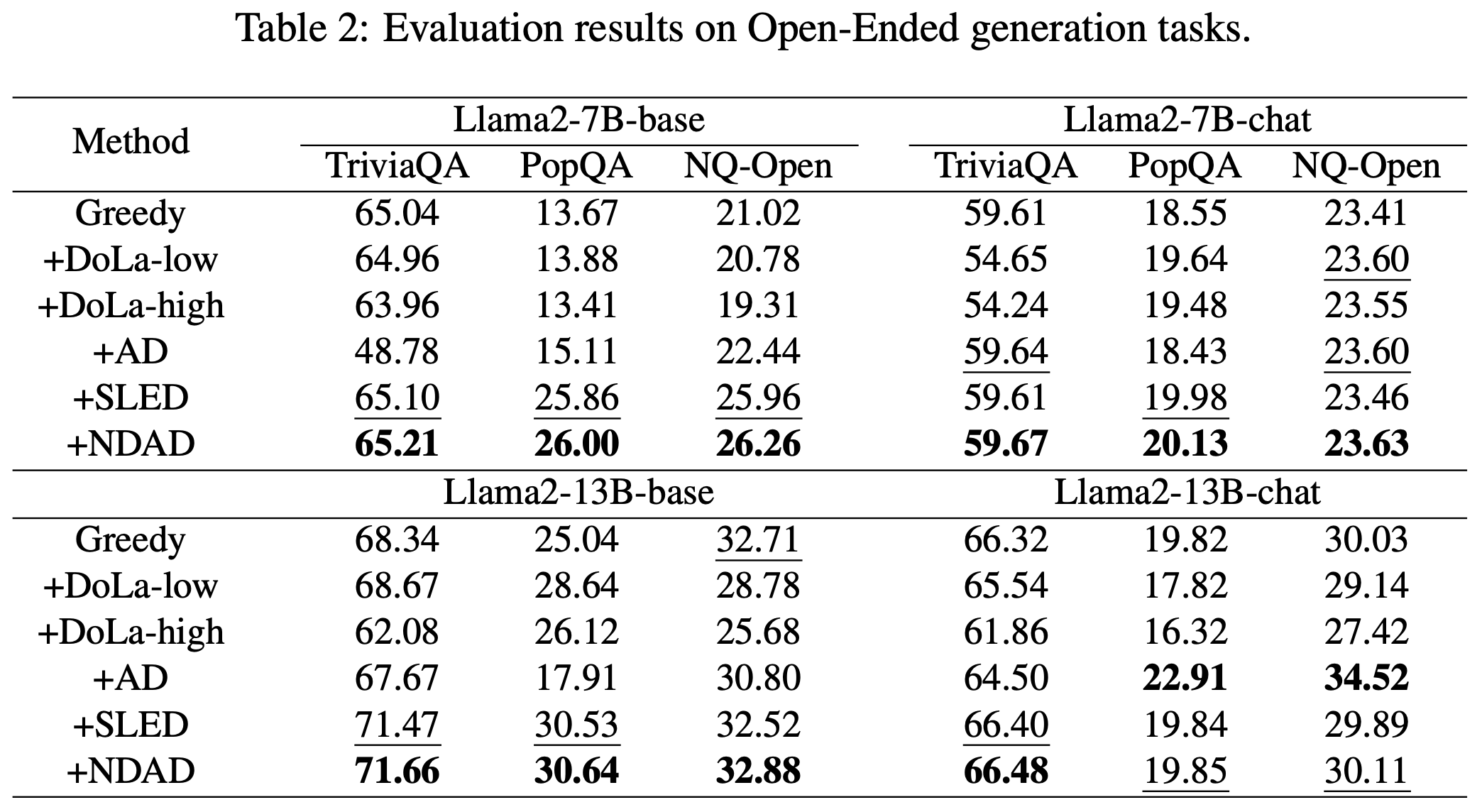 Table 2. Evaluation results on open-ended generation tasks.
Table 2. Evaluation results on open-ended generation tasks.
Open-ended generation is especially relevant because factual hallucination is not limited to multiple-choice scoring. On TriviaQA, PopQA, and NQ-Open, NDAD again improves over the main baselines in many settings.
The improvement pattern is modest but meaningful. Since NDAD does not use retrieval or extra training data, even small gains can be practically valuable if the method is stable and cheap enough to plug into existing decoding pipelines.
7.3 Different and larger LLMs
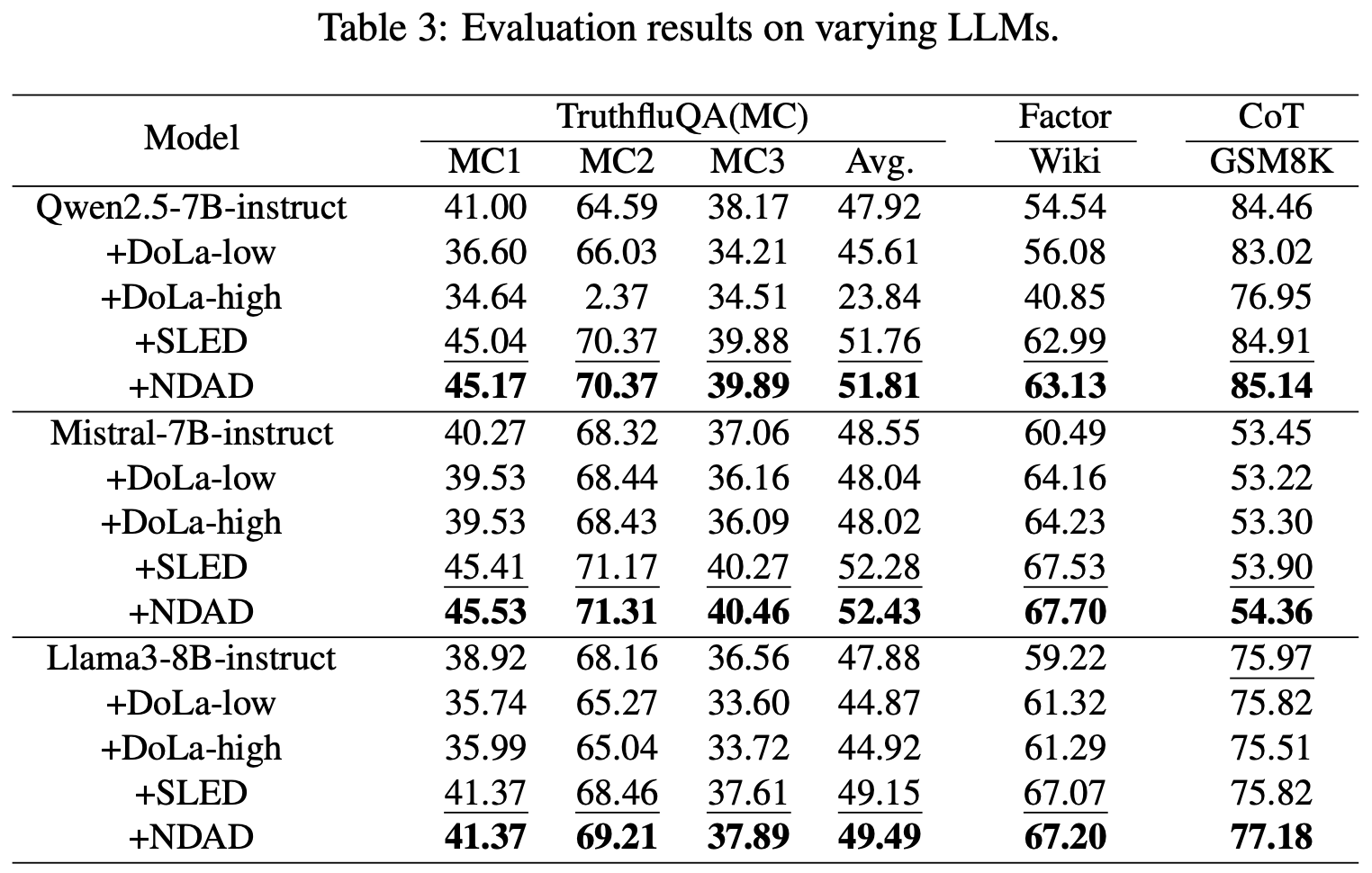 Table 3. Evaluation results on different LLMs.
Table 3. Evaluation results on different LLMs.
The paper also tests Qwen2.5-7B-instruct, Mistral-7B-instruct, and Llama3-8B-instruct. This is important because a decoding method should not only work on one model family.
The results suggest that NDAD generalizes reasonably well across different architectures. The gains are particularly noticeable on some CoT settings, which supports the paper’s claim that reasoning tasks are sensitive to internal attention-head disruption and correction.
8. Ablation: Does the Hallucination Signal Actually Exist?
One useful experiment is to decode from the masked signal itself.
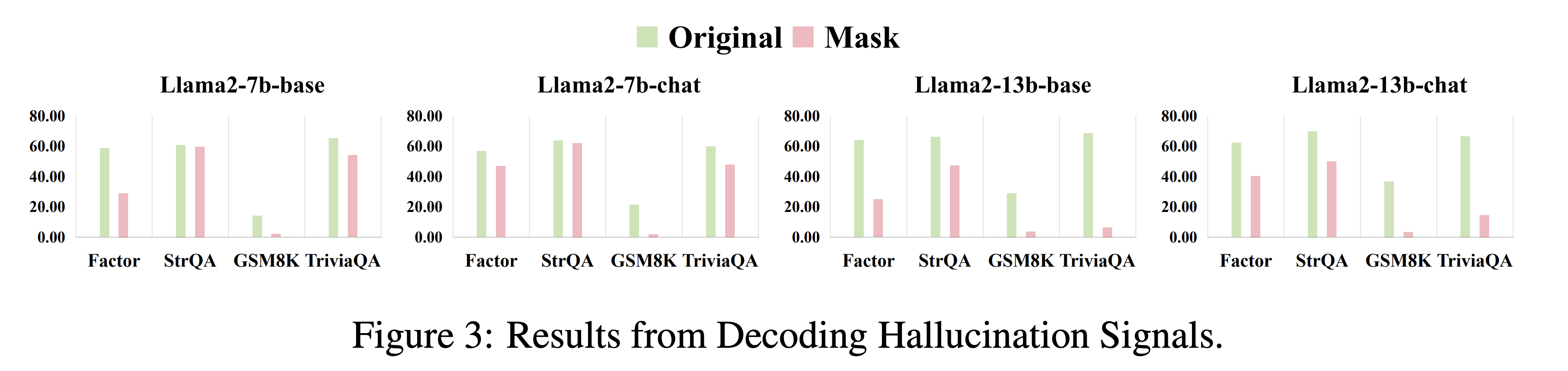 Figure 3. Results from directly decoding hallucination signals.
Figure 3. Results from directly decoding hallucination signals.
When important heads are masked and the model decodes from that weakened signal, performance drops. This supports the paper’s premise that masking important attention heads can inject a hallucination-prone signal.
The drop is especially meaningful on GSM8K. That makes sense because multi-step reasoning depends heavily on internal aggregation and stable intermediate states. If attention heads that support factual or reasoning structure are weakened, the model can drift more easily.
The paper also studies the number of masked heads and layers.
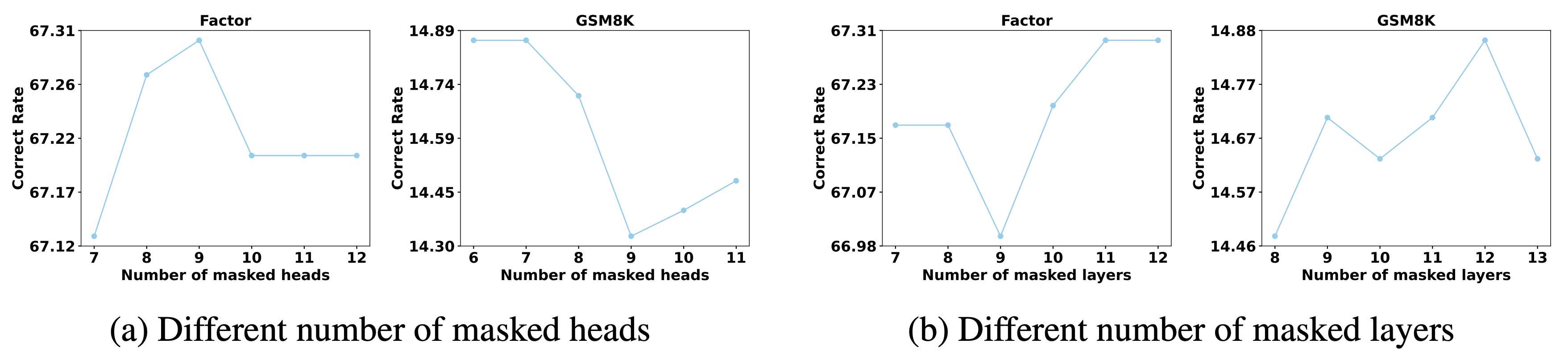 Figure 4. Effects of changing the number of masked heads and layers.
Figure 4. Effects of changing the number of masked heads and layers.
The general pattern is that masking too little may not create a strong enough signal, while masking too much may damage the model path too aggressively. In the experiments, using roughly 6 to 13 heads or layers tends to produce stable performance.
9. Limitations and Questions
The most interesting limitation is not simply runtime cost. It is the relationship between the proposed head-importance mechanism and the ablation results.
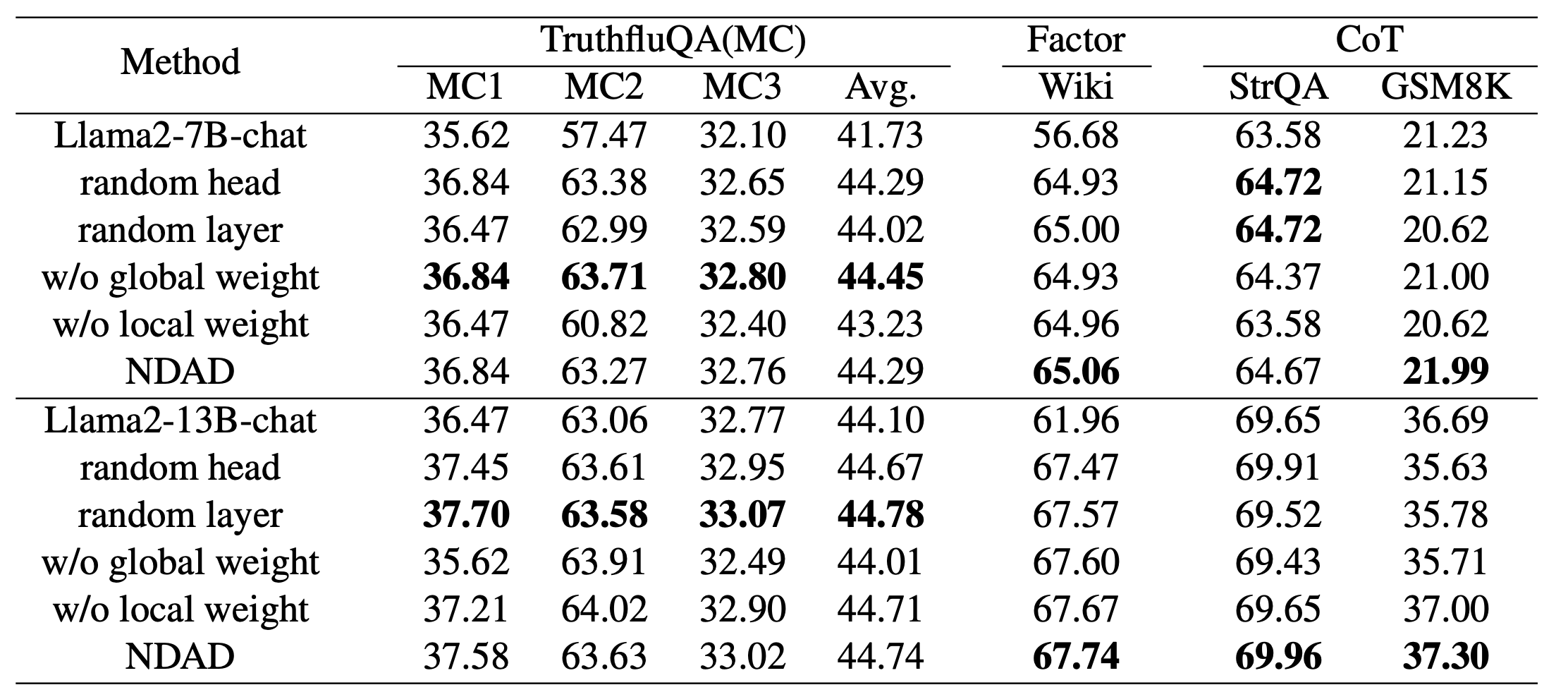 Table 6. Ablation study on NDAD components.
Table 6. Ablation study on NDAD components.
There are two points I would watch carefully.
First, random head or random layer selection can be surprisingly close to NDAD. In some rows, random masking is comparable to the proposed method. The paper explains that random masking may accidentally choose combinations related to factuality, but this still weakens the claim that the importance-guided selection is clearly necessary.
This does not invalidate NDAD as a decoding method. The method can still work. But it makes the mechanistic explanation less satisfying. If I were extending this paper, I would want repeated random trials with variance, confidence intervals, and a stronger comparison between importance-guided masking and random masking under the same masking budget.
Second, the global and local weights are both useful, but the local weight appears more critical in practice. Removing the local weight tends to hurt more in several cases, especially on reasoning-heavy settings. This matches the intuition that token-level risk matters more directly than layer-level signal reliability.
9.1 Computational overhead
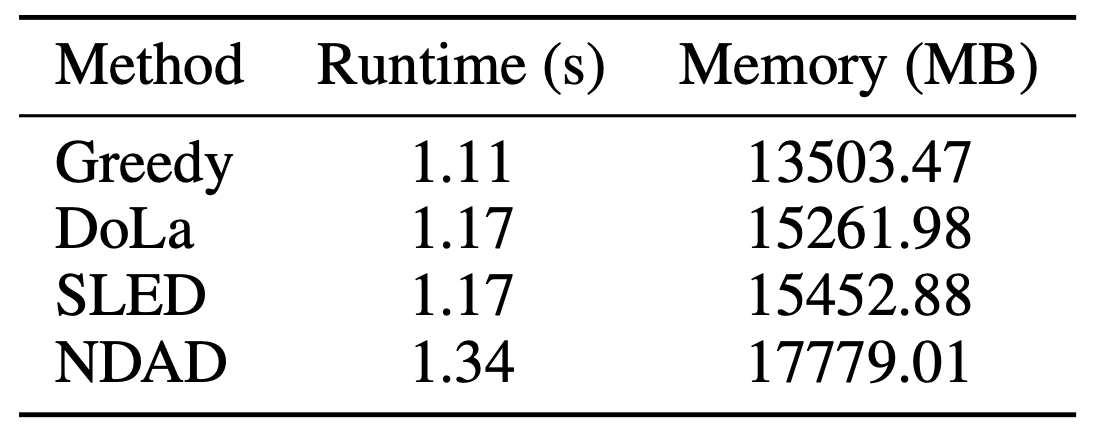 Table 5. Runtime and memory overhead on Llama2-7B-base / GSM8K.
Table 5. Runtime and memory overhead on Llama2-7B-base / GSM8K.
NDAD is training-free, but it is not cost-free. It must generate hallucination signals and compute the negative-direction adjustment. In the reported Llama2-7B-base / GSM8K setting, runtime and memory are higher than Greedy, DoLa, and SLED.
The overhead is still moderate for a decoding-time intervention, but this matters in production. If the serving system is latency-sensitive, NDAD’s extra computation must be justified by a measurable factuality gain.
10. Conclusion
NDAD is interesting because it reframes hallucination mitigation as a negative-direction problem.
Rather than only asking “which direction is factual?”, it asks:
“Can we expose the model’s hallucination-prone direction and subtract it during decoding?”
That framing is useful. It also fits a broader trend in LLM interpretability and decoding research: models may already contain both useful and harmful internal signals, and inference-time methods can sometimes steer generation by separating those signals.
My main takeaway is:
NDAD is a lightweight and practical decoding strategy, but the mechanistic claim around attention-head importance needs stronger evidence.
The paper’s results show that NDAD can improve factual reliability without retraining or retrieval. At the same time, the random masking ablation suggests that the method’s empirical success may not be fully explained by the proposed head-importance selection mechanism.
For me, that makes NDAD a good paper to study: the core idea is elegant, the results are useful, and the limitations point directly to follow-up research questions.