[PaRev] Large Language Model Based Fuzzing Techniques: A Survey
Fuzzing is one of the most popular miner of vulnerabilities. LLM also can do this?
![[arXiv] Large Language Model Based Fuzzing Techniques](/assets/img/posts/LLM_fuzzing/thumbnail.png)
First post after discharge! Now chipkkang9 will start analyzing with great interest in Security for AI. Let’s work hard until I become a world-class authority on AI security!
The first paper review is about a paper related to LLM Fuzzing.
I remember when I was doing the BoB 11th project, my sub-mentor asked me to look into OSS-Fuzzing. Why didn’t I think of digging into this properly then?
Before conducting proper AI security research, I brought a paper written on the interesting topic of LLM Fuzzing.
The paper information is as follows.
[ arXiv ] Large Language Models Based Fuzzing Techniques: A Survey
Linghan Huang, et al., University of Sydney, The University of Tokyo, University of Alberta
🪟 Abstract
As the IT era progresses, security and vulnerability analysis for software have become essential elements.
Fuzzing Test is one of the good tools for vulnerability analysis, and it is showing excellent performance in the software testing field based on LLM.
As software vulnerabilities continue to evolve, research on utilizing LLM-based Fuzzing Test is becoming active.
In this paper, we statistically analyze the latest research up to 2024 and discuss three areas:
- LLM
- Fuzzing Test
- LLM-based Fuzzing Test
Additionally, we explore the possibility that LLM-generated Fuzzing Test technology will be widely disseminated and applied in the future.
🙌 1. Introduction
A: “Bro, so don’t you do Fuzzing these days?” B: “Huh? I just set up a Fuzzing PC. It cost 20 million won.” A: “What is it that you even get a dedicated computer for?” B: “Fuzzing is like a kind of ‘blockchain mining’.” -From a conversation between a senior and me…
Fuzzing Test is a principle of checking software stability and security by generating a large amount of unintended inputs. As software develops, the importance of fuzzing tests is growing even more.
In particular, LLM-based Fuzzer is a new research topic, and several technologies appeared by the end of 2023. For example, there are TitanFuzz, FuzzGPT, etc.
This paper covers this field in more depth.
📜 1.1 Survey Contribution
This survey paper is developed based on three main research questions.
1. How is LLM utilized for Fuzzing Test in AI and non-AI fields? (Section 4.1, 4.2) 2. What are the advantages of LLM-based Fuzzers compared to traditional Fuzzers? (Section 4.1, 4.2) 3. What is the future development direction of LLM-based Fuzzers? (Section 5)
The key references and materials used in the paper are said to be in the GitHub link below, so it would be good to check it out. LLMs-based-Fuzzer-Survey // GitHub
🧐 1.2 Survey Scope and Literature Quality Assessment
This paper is written based on a total of 14 core papers, focusing on papers about the development, frameworks, or future prospects of LLM Fuzzing Test.
🖼️ 2. Background
🦾 2.1 Large Language Model(LLM)
The emergence of LLM has been a great help in performing various complex language tasks such as translation, summarization, information retrieval, and conversational interaction, because the Transformer was introduced and dramatically improved the model’s computational capabilities.
💡 What is a Transformer? A type of neural network architecture excellent for processing sequential data. Shows outstanding performance in fields such as Computer Vision, speech recognition, and time-series prediction. First presented in the 2017 paper, ‘Attention is All You Need’.
The structure of LLM models is largely divided into three types:
- Decoder-only Language Model
- Encoder-only Language Model
- Encoder-Decoder Language Model
The Encoder-Decoder structure is superior to other models in more complex language understanding and generation tasks.
📝 2.2 Fuzzing Test
Fuzzing Test, which first started in the 1990s, was used to verify software accuracy and reliability.
Before 2005, it was the early Fuzzing stage, and Black-box Fuzzing methods were used. This utilizes random mutation.
Between 2006 and 2010, Fuzzing based on Taint Analysis and Symbolic Execution began to develop in some Fuzzing systems, and various Fuzzing methods emerged.
Fuzzing development between 2011 and 2015 is characterized by three features:
- Coverage-Guided Fuzzing established itself as an important part.
- Various Scheduling Algorithms were applied to Fuzzing.
- A trend of combining multiple techniques to increase Fuzzing efficiency strengthened.
In 2016 and 2017, Fuzzing systems based on AFL (American Fuzzy Loop) became more common. At this time, ML concepts were also introduced to Fuzzing.
Even at this moment, Fuzzing is continuously evolving and is largely classified into two types:
- Mutation-based Fuzzing Test
- Generation-based Fuzzing Test
These two types of Fuzzers are used for different types of software.
Also, depending on the Program Under Test (PUT), it is divided into three types:
- Black-box Fuzzer: Generates inputs randomly using predefined Mutation rules without prior information about PUT.
- White-box Fuzzer: Generates Test-cases using information about PUT, theoretically capable of covering all program paths.
- Grey-box Fuzzer: Adjusts Mutation strategies by obtaining some information such as Code-coverage during Fuzzing execution.
🎥 3. LLM Based Fuzzing test Analysis
🥲 “What if a Fuzzer could automatically create more probable mutations?”
While I was doing BoB 11th, I also used Fuzzers, but I always had the above question.
It would have been best if I had started research at the same time as having this question, but I just left it as curiosity and did nothing, and while I disappeared at the call of the country, a paper like this was written.
Traditional Fuzzing Test has met limits in many areas, and many researchers have started to combine LLM and Fuzzing Test to increase efficiency and accuracy.
As a result of comprehensive analysis, LLM-based Fuzzers tend to apply LLM technology to:
- Prompt Engineering
- Seed Mutation
for Fuzzing Test performance improvement.
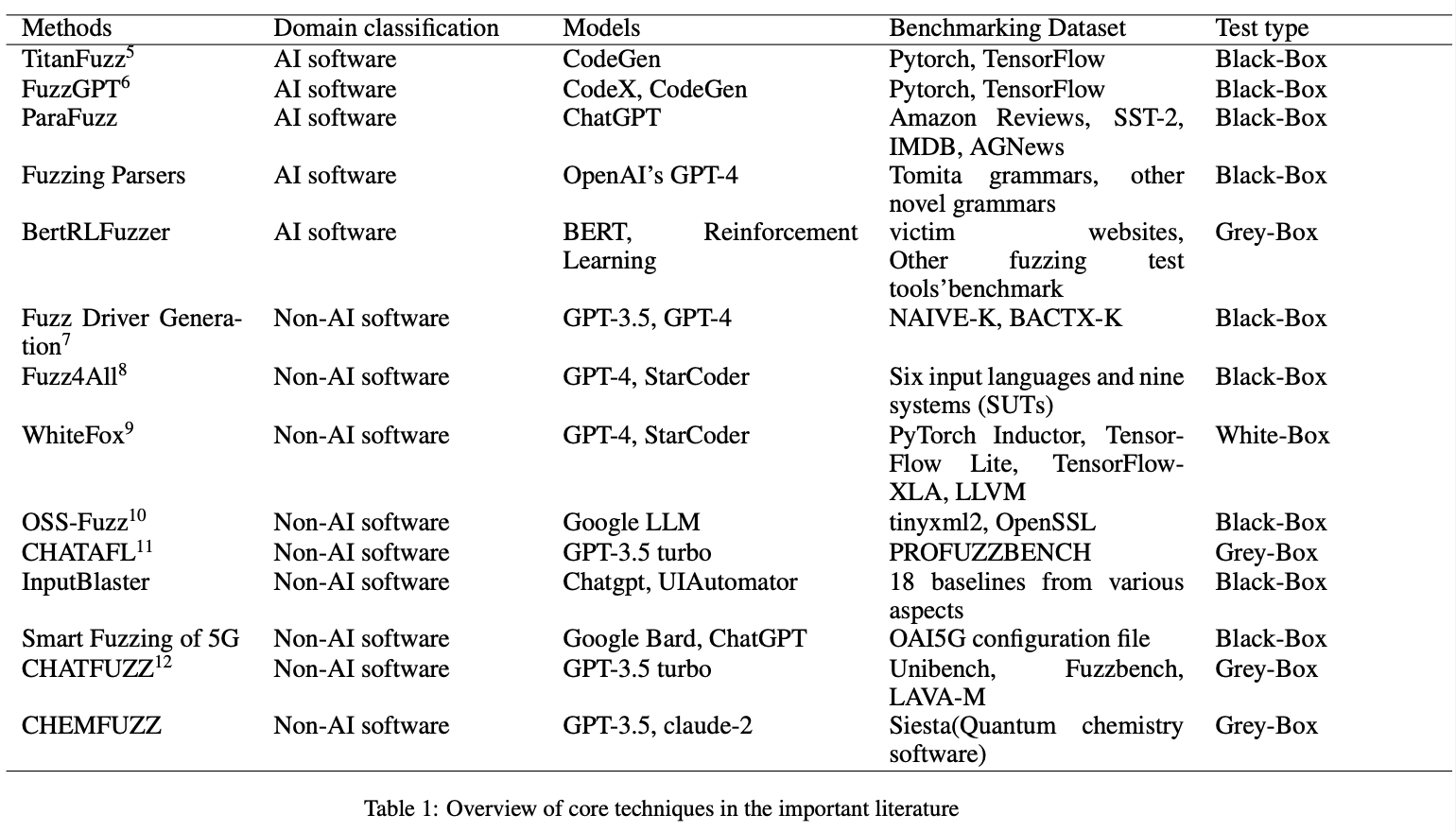
In this paper, metrics for evaluating Fuzzing Test performance based on all technologies are summarized, and based on 14 core documents, models, benchmarks, test types, etc., are classified and discussed in Chapters 4 and 5.
💀 3.1 AI Software
Q. How do developers use LLM for Fuzzing Test?
In Fuzzing Test of AI-type software, different software has different test methods, and various defense methods exist for various attack methods.
- 「ParaFuzz: An Interpretability-Driven Technique for Detecting Poisoned Samples in NLP」
- Lu Yan, et al., NeurlPS Proceedings, 2023
- ParaFuzz is a Framework for detecting backdoor attacks (malicious code injection) in NLP (Natural Language Processing) models.
- Utilizes ChatGPT 3.5 to transform Trigger removal into a Prompt Engineering task, and applies Fuzzing techniques to derive optimal interpretation prompts.
- 「Large Language Models for Fuzzing Parsers」
- Joshua Ackerman and George Cybenko, ISSTA, 2023
- Automatically generates data objects from natural language formats using OpenAI’s GPT-4 and text embedding model (text-embedding-ada-002), conducting tests on various data formats.
- 「BertRLFuzzer: A BERT and Reinforcement Learning Based Fuzzer」
- Piyush Jha, et al., AAAI, 2024
- Combines BERT model and reinforcement learning technology to automatically detect web vulnerabilities (SQL Injection, XSS, CSRF, etc.).
- BERT learns syntactic fragments of Attack Vectors and performs automatic input tests as mutation operators based on reinforcement learning.
- 「Large Language Models Are Zero-Shot Fuzzers: Fuzzing Deep-Learning Libraries via Large Language Models」
- Yinlin Deng, et al., ISSTA 2023, 2023
- The first technology to test DL libraries using LLM.
- Utilizes CodeX and CodeGen models to mutate seeds and performs Fuzzing Test based on evolutionary algorithms.
- 「Large Language Models are Edge-Case Generators: Crafting Unusual Programs for Fuzzing Deep Learning Libraries」
- Yinlin Deng, et al., ICSE’24, 2024
- A technology developed after TitanFuzz, it analyzes code that triggered vulnerabilities to generate more complex and specific edge-case code.
- While TitanFuzz directly generates/modifies code snippets, FuzzGPT works based on few-shot, zero-shot learning, and Fine-Tuning techniques.
Prompt Engineering and Seed Mutation
Existing Mutation-based Fuzzers mainly focus on simple operations such as BitFlipping, arithmetic mutation, block-based mutation, and dictionary-based mutation.
LLM-based Seed Mutation utilizes context awareness and natural language processing capabilities to perform complex mutations such as rewriting code fragments, changing data structures, and simulating user interaction while maintaining the file format.
In the ParaFuzz paper, to perform Mutation Operations, a Meta Prompt to solve the problem was presented using ChatGPT.
💡 What is Meta Prompting? A technique of writing meta-level prompts that tell the model “how to think or answer”. A strategy to increase the quality and direction of responses through high-level instructions before the model generates an answer. Source: Meta Prompting and major prompt engineering techniques 😋
TitanFuzz generates a large amount of initial input data based on CodeX, masks part of it, and fills it with CodeGen to create various inputs. Specific Mutation methods include Parameter mutation, prefix/suffix mutation, Method mutation, etc.
📟 3.2 Non-AI Software
Q. How do developers use LLM for Fuzzing Test?
Fuzzing Test is also used for software where AI technology is not used.
- 「Fuzz4All: Universal Fuzzing with Large Language Models」
- Chunqiu Steven Xia, et al., ICSE’24, 2024
- A universal fuzzer capable of automatically testing projects written in various programming languages utilizing GPT-4 and StarCoder.
- Utilizes the strengths of both models to understand the meaning of syntax and efficiently generate inputs and perform mutations in multi-language environments.
- Fuzzing can be performed on Projects, Programs, and even API libraries.
- 「WhiteFox: White-Box Compiler Fuzzing Empowered by Large Language Models」
- Chenyuan Yang, et al., ACM Journals, 2024
- A White-box Fuzzing technique for Compilers, it divides two LLM models (GPT-4 / StarCoder) into an analysis LLM and a generation LLM to create optimized test programs.
Fuzz4All and WhiteFox have some similarities as they use the same LLMs and have consistent target test objects.
While GPT-4 has powerful natural language understanding and analysis capabilities, the cost required to generate input values is quite high.
Therefore, in Fuzz4All and WhiteFox, GPT-4 is used as an analysis LLM technology for understanding, requirement analysis, and information extraction, and StarCoder is utilized for continuous and efficient input value generation.
📚 Use of LLM-based Fuzzer by field
- Network Protocol Testing (CHATAFL)
- Grey-box Fuzzing (ChatFuzz)
- Quantum Chemistry (ChemFuzz)
- Mobile Applications (InputBlaster)
- 5G Wireless Software (Applying AFL++ to OAI5G model)
+) LLM developed by Google was applied to the OSS-Fuzz Fuzzing system and succeeded in improving project code coverage.
Prompt Engineering and Seed Mutation
Prompt Engineering and Seed Mutation are still important in Fuzzing Test for non-AI software using LLM, but there are some differences from traditional Fuzzing Test approaches.
- Fuzz4All
- Summarizes complex user inputs into concise prompts using LLM, through which Generative LLM creates code snippets (seeds).
- Also, updates the input prompt at each iteration to prevent duplicate generation.
- InputBlaster
- Generates a Test Generator using LLM based on mobile app UI information.
- Takes the constraints output by LLM as the next Mutation rule to be used in the next iteration.
🆚 3.3 Comparison between LLMs-based Fuzzer and Traditional Fuzzer
! LLMs-based Fuzzer VS Traditional Fuzzer compared in the paper
LLMs-based Fuzzer VS Traditional Fuzzer compared in the paper
Compared to traditional Fuzzers, LLM-based Fuzzers have the following advantages:
Higher API & Code Coverage:
- TitanFuzz showed 91.11% and 24.09% improved API Coverage in TensorFlow and PyTorch, respectively (compared to the Fuzzers below):
- FreeFuzz (Wei et al., 2022)
- DeepREL (Deng et al., 2022)
- LEMON (Wang et al., 2020)
Muffin (Gu et al., 2022)
- ChatAFL increases the detection range and the possibility of finding undiscovered bugs with an average of 5.8 - 6.7% more coverage (compared to the Fuzzers below):
- AFLNET (Pham et al., 2020)
- NSFuzz (Qin et al., 2023)
Generate more efficient Programs:
In terms of overall code, TitanFuzz achieved code coverage of 39.97% and 20.98% in TensorFlow and PyTorch, exceeding DeepREL and Muffin.
TitanFuzz has more time cost, but by using only the seed generation function, testing for APIs covered by DeepREL is superior to DeepREL and takes less time, which is an advantage of directly using LLM to generate high-quality seeds.
🧐 Time Cost of LLM-based Fuzzing…. Compared to simple Mutation-based Fuzzing, LLM-based Fuzzing will have heavy Time Cost in many aspects. How can this be solved? It might be solved by using only the seed generation function like TitanFuzz, but is this method consistent with the purpose of LLM-based Fuzzing?
Found more complex errors:
❗️Problem of Traditional Fuzzer: It does not understand code structure or logic as it derives Randomly Generated Test Cases. Therefore, it has low efficiency in identifying advanced vulnerabilities or program patterns.
✅ Advantage of LLM-based Fuzzer: It has a strength in finding new and complex vulnerabilities by learning past bug data.
ex1. FuzzGPT found a total of 76 bugs, 61 were confirmed, 49 were undiscovered bugs, and 6 were found to be patched bugs. More importantly, FuzzGPT found 11 high-impact bugs or security vulnerabilities.
ex2. When comparing CHATAFL (LLM-based) and NSFUZZ, AFLNET (Traditional), within the same number of executions and time, CHATAFL found 9 new vulnerabilities while NSFUZZ found 4 and AFLNET found 3.
Increased Automation:
Traditional Fuzzers mainly require manual work and cost, but LLM-based Fuzzers automate Seed generation and Mutation, saving Testing Cost and time.
🗣️ 4. Discussion on Future Work
✌️ 4.1 Two types of LLM-based Fuzzers
LLM-based Fuzzer can be largely divided into two sections.
- 1️⃣ The First Part.
- Collect past datasets of Target Software, classify error codes and vulnerabilities in data, and train the model.
- Build a Professional Fuzzer Model by learning past information.
- Utilize for testing by training as a Professional Fuzzing Model.
- 2️⃣ The Second Part.
- Introduce LLM into specific stages of the Traditional Fuzzing Process to improve performance.
- ex. TitanFuzz (CodeX + CodeGen)
Comparing FuzzGPT and TitanFuzz, which are representative examples of the two models, **'The First Part' LLM-based Fuzzer is more promising**.
📊 4.2 Discussion of Pre-Training Data
To develop a Professional Fuzzing Model, the quality and quantity of Pre-Training Data are very important.
Bias of datasets, repeatability and size of pre-training data can affect performance, and if there is a lot of redundant data, the model can heavily rely on certain data.
Therefore, improving data quality and quantity is very important! Solving this challenge is expected to be one of the keys to future success.
⏰ 4.3 Discussion of Time Consuming
Deep Learning models used for LLM require a lot of computation and time to generate code.
🧐 Taking TitanFuzz as an example, Generating code and meaningful Code Snippets takes a lot of time as it must go through repetitions and adjustments several times. Duplicate verification and filtering processes are also needed to generate various programs, and API calls of DL libraries require complex data structures and operations, thus taking more time.
As I left as a natural question in Section 3.3 while writing the blog, research for automation and optimization in the Time Cost problem is necessary in LLM-based Fuzzing.
💯 4.4 Discussion of Evaluation Framework for Large Language Model-based Fuzzing Test
Criteria for evaluating Fuzzer will be set differently depending on the goal.
- The number of vulnerabilities found and Code Coverage are the most important evaluation factors.
However, code coverage and vulnerability discovery are not always related.
Therefore, a comprehensive and standardized evaluation framework is needed.
The framework should consider performance comparison by LLM type used, evaluation under consistent environments and conditions, and actual vulnerability discovery capability.
🚗 4.5 Discussion of Achieving Full Automation
LLM-based Fuzzer has the advantage that manual work has been greatly reduced compared to existing Fuzzers, but full automation of the entire process remains a technical challenge.
📑 5. Conclusion
This paper provides a review and summary of Fuzzing Test technology using LLM models, and covers methodologies applicable to both AI-type software and non-AI-type software.
- LLM-based Fuzzer holds advantages in terms of API and code coverage, advanced bug discovery, and automation efficiency.
- Therefore, it is evaluated as having significant potential in the future SW Testing field.
👋 Epilogue. Paper Review
As it is a Survey paper, it does not cover technical details in depth.
However, while using Fuzzers myself, I also imagined ‘Wouldn’t it help Coverage if GPT automatically and quickly generated input values?’
Because of that, the researchers of LLM-based Fuzzer covered in this paper felt welcoming to me.
LLM-based Fuzzing technology seems to be a field that needs more research.
Not long ago, when talking about related stories with a senior, we talked about the limitations mentioned at the end of this study, and I think that in order to seek ways to improve those limitations, more understanding of Deep Learning itself is needed.
This is the first blog post after discharge, and I should work hard to research, study, and organize so that I can continue this posting habit in the future.