[PaRev] Recurrent Neural Network based Language Model
The very first RNN based Language Model, the fundamental of NLP
![[INTERSPEECH 2010] Recurrent neural network based language model](/assets/img/posts/RNNLM/thumbnail.png)
During my military service, I met really great successors and studied LLM-related topics. Although I didn’t read papers at the time to build a foundation since I had no knowledge of AI, my successors were so passionate that they even formed a study group in the military to understand LLM. (I have so much respect for them…)
Having become interested in AI security only as I approached discharge, I’m now trying to catch up late.
The information for the paper to be reviewed in this post is as follows.
[ INTERSPEECH 2010 ] Recurrent Neural Network based Language Model
Toma´s Mikolov et al., Brno University of Technology, Johns Hopkins University
🧐 Abstract
This paper is the first to propose a language model based on RNN (Recurrent Neural Network).
I plan to review the papers that served as the foundation for today’s LLMs (Large Language Models), from RNNLM to GPT. I hope my blog helps those interested in LLM.
The paper mentions that RNN was born to overcome the limitations of the existing N-gram technology, a word prediction technique, and to devise a technology that could be used for speech recognition.
🙌 1. Introduction
As mentioned in the abstract, the background of RNN’s emergence is to overcome the limitations of existing N-gram technology.
A language model like N-gram, which calculates the probability of a specific word by looking at surrounding words, is called a “Statistical Language Model (SLM).”
📊 Statistical Language Model
Before understanding RNN-based language models, Statistical Language Models (SLM) were used. An SLM refers to a model that predicts words based on the Markov Assumption.
🤷♂️ What is the Markov Assumption?
It is the assumption that the future state is determined solely by the current state, ignoring the process leading up to the current state. The Markov Assumption is based on conditional probability, meaning that an event occurring now happens based on other events that have already occurred.
\[P(S_t|S_{t-1}, S_{t-2}, ... , S_1) = P(S_t | S_{t-1})\]💀 Limitations of SLM
Predicting the next word based on N previous words is called an N-gram language model. For example, an N-gram model based on 2 words is called a bigram, and 3 words a trigram.
The number of previous words (N) examined to predict a single word is called a ‘window’. If N is small, the time taken for word prediction is short, but accuracy is low. This problem is called the ‘Long-Term Dependency Problem’.
Conversely, if N is large, accuracy increases relatively, but the time for word prediction becomes longer. As the training data (Corpus) grows, the opportunity cost increases, a problem known as the ‘Sparsity Problem’.
Therefore, the Trade-off process of determining a value for N that is neither too large nor too small is very important. Generally, in academia, it is known that it is good to maximize the size of N but not exceed 5.
👼 Overcoming Limitations
💡 However, even if the value of N is determined to be a decent size, the design of N-gram itself is quite fatal from the perspective of a language model. Why is that?
Naturally, there are limits to predicting a word in a sentence based only on looking up fixed previous words.
The method that emerged to overcome these problems is utilizing Artificial Neural Networks for word prediction tasks. Based on this idea, technologies like LSTM language models, BERT, and GPT began to be developed.
Using RNN (Recurrent Neural Network) can overcome the limitations of existing models (SLM) that predicted new words by referring only to fixed-length words. A language model based on RNN is called an RNNLM (RNN based Language Model).
📜 2. Model Description
✖️ Understanding with MathLines!
In RNNLM, the variable for the current time is expressed as $t$. In this network, let the input layer be $x$, the hidden layer be $s$, and the output layer be $y$. The input at current time $t$ is $x(t)$, the output is $y(t)$, and the hidden layer (state of the network) is $s(t)$.
The value of vector $x(t)$, which is the input value, is determined by $w(t)$, the vector representing the current word, and $s(t-1)$, the state of the previous hidden layer.
\[x(t) = w(t) + s(t-1)\]The hidden layer (context/hidden layer) plays a role in remembering past information. It is determined by summing the results of multiplying the input layer values calculated above by weights. This value is reused when calculating the output layer and when determining the input layer for the next time step.
At this time, the activation function $f(z)$ uses the sigmoid function.
\[s_j(t) = f \left( \sum_i x_i (t) u_{ji} \right) \; \text{where,} \; f(z) = \frac{1}{1+e^{-z}}\]Once the hidden layer calculation is complete, the output layer is derived based on the results of the hidden layer.
At this time, the function $g(z_m)$ uses the softmax function.
\[y_k(t) = g \left( \sum_j s_j(t) v{kj} \right) \; \text{where,} \; g(z_m) = \frac{e^{z_m}}{\sum_k e^{z_k}}\]Additionally, the Cross-Entropy function is used as the Loss function in the process of training the RNNLM Network.
🌇 Understanding with Pictures!
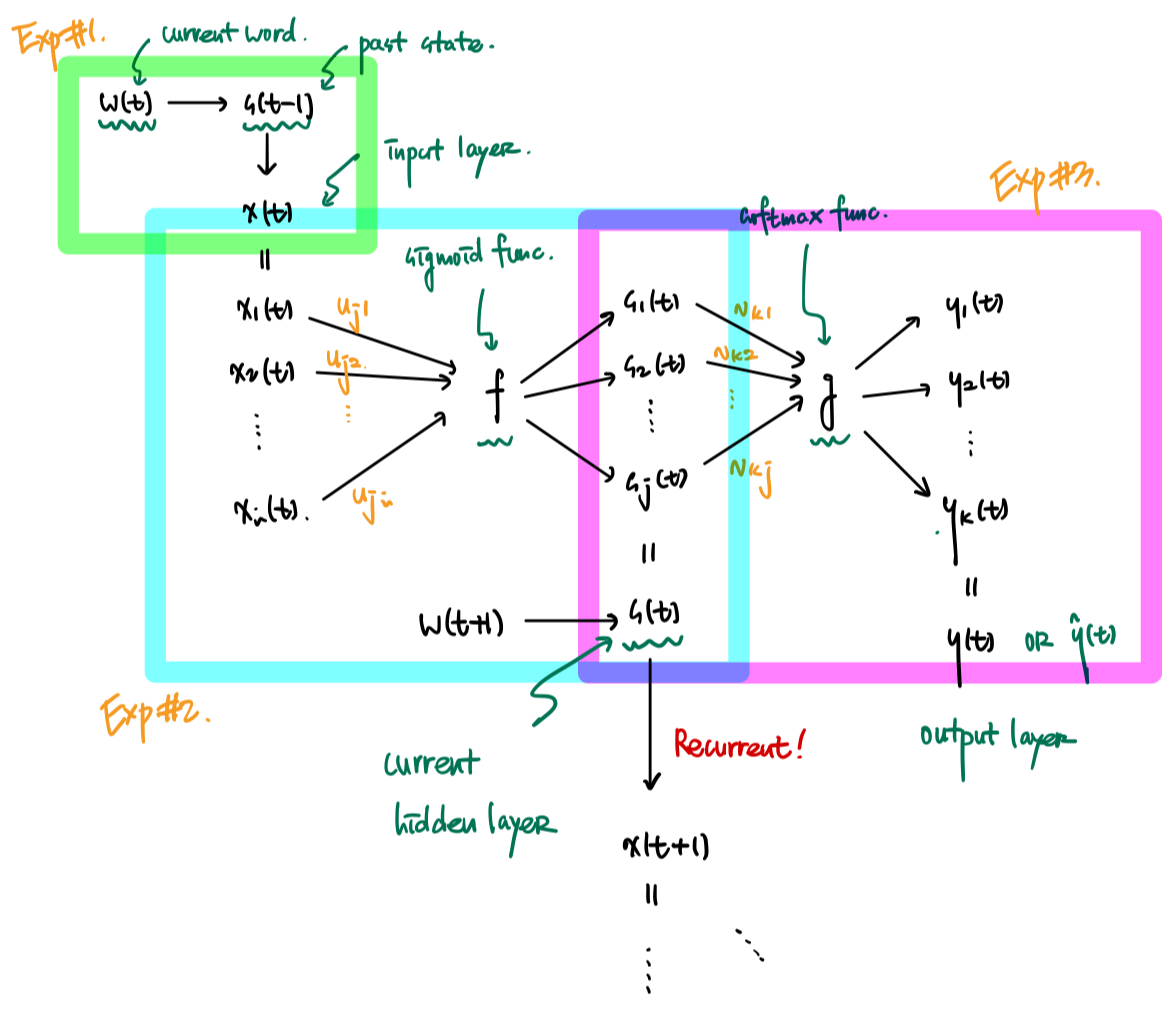
The picture above shows the structure of RNNLM explained in the paper.
💡 SLM vs RNNLM Compared to models that predict words by looking at words of a certain length (e.g., N-gram), the concept of processing by looking at context was born.
📚 Network Learning
The network is trained using backpropagation and stochastic gradient descent.
- Backpropagation
- A method of updating weights by calculating from the output layer toward the input layer.
- It involves repetitive weight update processes: weights between output layer and the immediate previous hidden layer, weights between that hidden layer and the one before it, and so on.
- Stochastic Gradient Descent (SGD)
- A representative optimization algorithm used in Deep Learning.
- Calculates gradients and updates parameters using one or a few training samples.
- Contributes to reducing costs for calculation and non-linear optimization.
🧨 Dynamic Model
While typical models do not update weights during the testing phase, a Dynamic model continues learning even while processing test data. This allows it to automatically adapt to new words or domains, producing an effect similar to a cache.
💡 Static Model vs. Dynamic Model
- Static Model: Learned offline; the model is learned once and used, then needs to be learned again.
- Dynamic Model: Learned online; data is continuously input into the system and integrated into the model through these updates.
🔭 3-4. Experiment (WSJ, NIST RT05)
As a result of speech recognition experiments with the Wall Street Journal (WSJ) and NIST RT05 meetings:
RNNLM showed a larger performance improvement as the training data increased compared to the 5-gram model, and it was noted that higher performance could be achieved when the Dynamic Model was applied.
🔮 5. Conclusion & Future Work
🖊️ Conclusion
Significantly better performance than existing SLM (N-gram) a. Excellent performance with less data b. Innovation of the model itself
Presentation of the possibility of Online Learning a. Emergence of the Dynamic Model b. Designed to adapt to real-time information and fit the concept of Learning
📑 Future Work
🧐 What’s NEXT?
- Improvement of learning algorithms
- The paper used an algorithm called truncated BPTT, but hopes for the application of a full BPTT algorithm.
- (Additional summary planned)
- Connection and scalability with other fields
- Machine Translation, Optical Character Recognition (OCR), etc.
- Possibility of combining with other disciplines
❗️ Still, Limitations
- Long-Term Dependency Problem
- The author is impressive for clearly identifying the limitations of his own model.
- Mentioned that Vanilla (Simple) RNN cannot include information from long contexts.
- Triggered the emergence of models like LSTM and GRU.
- High Computational Cost
- RNNLM requires much more time and computational resources compared to N-gram.
- Representatively, the composition of Word Vectors consists of one-hot encoding, causing spatial problems!
- Triggered the emergence of Word2Vec.
👋 Epilogue. Paper Review
This paper came out when I was just learning multiplication tables at school in 2010. Since it’s the first paper for LLM, it took quite a while to read, but I spent time because I wanted to understand it perfectly.
Personally, I think there are still gaps in my perfect understanding, so I should try to fill those gaps.
I think AI is a good field because there is so much to study. To write this one blog post, I looked up so many articles, and there’s a mountain of things left to study.
I want to conquer LLM quickly yet accurately and systematically and then move on to the Vision side!
There are so many concepts that appear while reviewing this paper; I will definitely post them on the blog!!