[PaRev] Programming Refusal with Conditional Activation Steering (CAST)
A review of CAST, an activation steering method for selectively applying refusal behavior without fine-tuning.
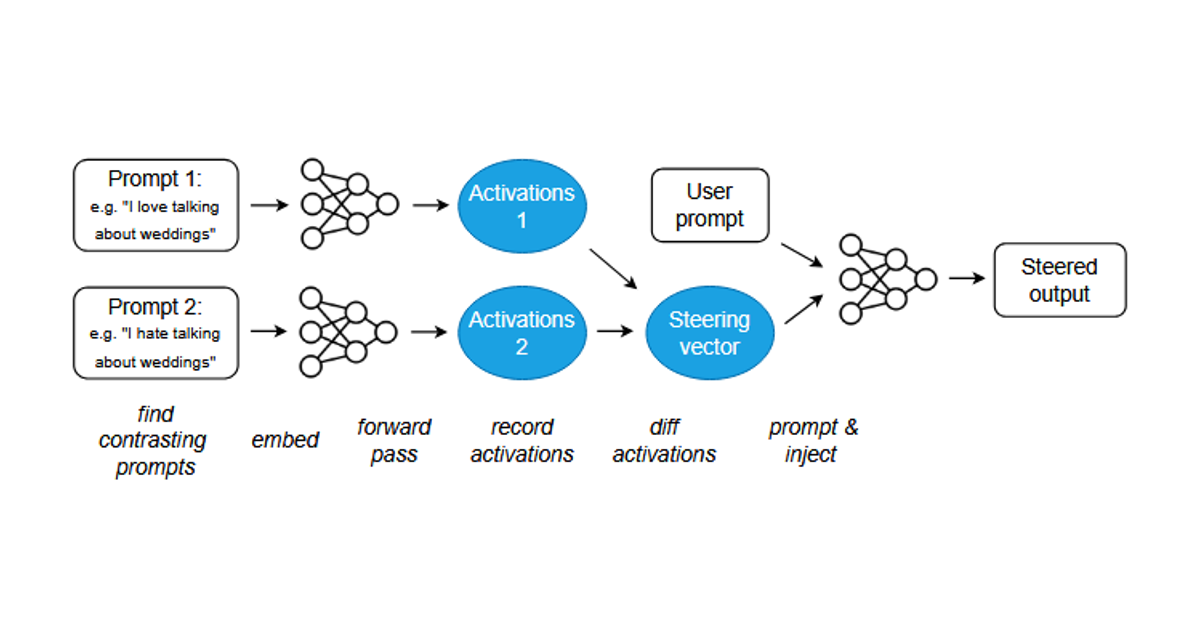
On February 20, 2026, I reviewed Programming Refusal with Conditional Activation Steering.
[ ICLR 2025 Spotlight ] Programming Refusal with Conditional Activation Steering
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, Amit Dhurandhar
University of Pennsylvania, IBM Research
The paper proposes Conditional Activation Steering (CAST), an activation steering method that selectively applies or withholds a behavior vector depending on the input context. Its core question is practical:
Can we make a language model refuse only under the conditions we actually care about, without fine-tuning the model weights?
The paper is about refusal, but I think the broader theme is more interesting than refusal itself. CAST treats behavior control as something closer to programming over hidden states:
1
2
if the prompt is about a target condition, apply this behavior vector
otherwise, leave the model mostly unchanged
All figures in this post are extracted from the original paper/presentation material. I did not generate any synthetic figures or use full-slide screenshots.
Additional resources: arXiv:2409.05907, IBM activation-steering, and AISteer360 CAST demo.
1. Motivation: Activation Steering Without Conditional Control
Activation steering modifies a model’s internal activation during inference. A common formulation is:
\[h' \leftarrow h + \alpha v\]where $h$ is a hidden state, $v$ is a steering vector, and $\alpha$ controls the intervention strength.
This is attractive because it does not require weight optimization. If we can find a direction associated with refusal, helpfulness, sentiment, or another behavior, we can add that direction during generation.
However, ordinary activation steering has a major limitation:
It changes behavior broadly, even when the intervention should only apply to a subset of inputs.
For refusal behavior, this becomes a serious problem. A refusal vector may make the model safer on harmful prompts, but it can also make the model over-refuse harmless prompts.
This is why CAST introduces conditional control. Instead of always applying a refusal vector, CAST asks whether the current hidden state looks like it belongs to a target condition. Only if the condition is satisfied does the method apply the behavior vector.
The intended use case is not only “make the model refuse more.” It is closer to:
1
2
3
4
if the input is about hate speech or adult content, refuse
if the input is not about health, refuse
if the input is about legal advice, refuse
otherwise, comply normally
That framing matters because refusal is context-dependent. The same information can be safe or unsafe depending on domain, user role, jurisdiction, or policy.
2. Core Observation: Prompts Leave Different Activation Patterns
CAST is built on a simple observation:
Different classes of prompts consistently activate different patterns in hidden states.
If harmful prompts and harmless prompts occupy separable regions in activation space, then a vector can be used as a condition indicator. The condition vector does not directly produce refusal. It acts as a detector for when another vector should be applied.
This separates two roles that are often collapsed in simple steering:
| Vector | Role |
|---|---|
| Condition vector $c$ | Detects whether the current hidden state satisfies a concept or condition |
| Behavior vector $v$ | Modifies the model behavior, such as inducing refusal |
This separation is the key design choice. The behavior vector answers “what behavior should be added?” The condition vector answers “when should that behavior be added?”
3. CAST Formulation
The paper formulates conditional activation steering as:
\[h' \leftarrow h + f(\mathrm{sim}(h, \mathrm{proj}_c h)) \cdot \alpha \cdot v\]where:
| Symbol | Meaning |
|---|---|
| $h$ | hidden state at inference time |
| $c$ | condition vector |
| $v$ | behavior vector |
| $\alpha$ | behavior vector strength |
| $\mathrm{sim}$ | cosine similarity |
| $\mathrm{proj}_c h$ | projection of $h$ onto $c$ |
| $f$ | trigger function that decides whether to apply $v$ |
The projection term can be understood as asking:
How much of the current hidden state points in the direction of the condition vector?
One way to write the projection is:
\[\mathrm{proj}_c(h) = \frac{h \cdot c}{c \cdot c}c\]Then CAST compares the current hidden state against its condition-projected component. In the simple step-function version:
\[f(x) = \begin{cases} 1 & \text{if } x > \theta \\ 0 & \text{otherwise} \end{cases}\]In practice, the threshold $\theta$, comparison direction, and intervention layer are hyperparameters. The comparison direction is important because the model may separate a concept in either direction depending on the layer and model.
4. Extracting Condition and Behavior Vectors
CAST starts from contrastive examples. For refusal, the paper uses datasets such as Sorry-Bench for harmful prompts and Alpaca-style harmless prompts. The method then extracts directions from hidden states.
The high-level pipeline is:
- Gather positive and negative examples.
- Extract a behavior vector $v$ and condition vector $c$.
- Search for the best intervention point.
- Apply steering during inference.
The slides summarize vector extraction as:
\[H_l^+ = \text{hidden states for positive examples at layer } l\] \[H_l^- = \text{hidden states for negative examples at layer } l\]Then the hidden states are mean-centered:
\[\mu_l = \frac{H_l^+ + H_l^-}{2}\]and PCA is used to obtain a vector direction:
\[\mathrm{vector}_l = \mathrm{PCA}(H_l^+ - \mu_l, H_l^- - \mu_l)\]Conceptually, this is similar to many representation-engineering methods: if two groups of examples differ by a target concept, the difference in their internal representations can provide a useful steering direction.
The extra step in CAST is that the extracted vector is not only used to push behavior. It can also be used as a condition detector.
5. Conditioned Refusal: Refuse Harmful, Comply Harmless
The main experiment asks whether CAST can increase refusal on harmful prompts while keeping harmless refusal low.
The setup in my slide summary was:
| Component | Description |
|---|---|
| Harmful prompts | 45 harm categories from Sorry-Bench |
| Generated harmful prompts | 90 harmful prompts for each category, 4,050 total |
| Harmless prompts | benign instructions matched to harmful prompts |
| Search target | threshold $\theta$, layer $l$, and comparison direction |
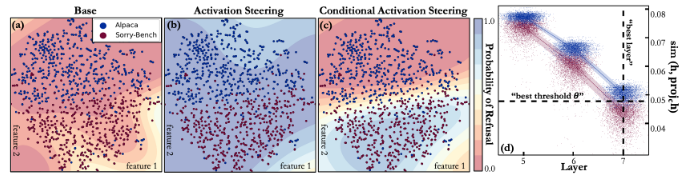

The important comparison is between ordinary activation steering and conditional activation steering.
| Model | Base harmful refusal | Base harmless refusal | + Refusal harmful | + Refusal harmless | + Condition harmful | + Condition harmless |
|---|---|---|---|---|---|---|
| Qwen 1.5 1.8B | 45.78% | 0.00% | 100.00% | 96.40% | 90.67% | 2.20% |
| OLMo SFT | 53.11% | 5.20% | 93.33% | 89.60% | 86.22% | 6.00% |
| Hermes 2 Pro | 19.33% | 1.00% | 98.00% | 91.80% | 83.33% | 2.40% |
This is the central result:
Ordinary refusal steering increases refusal almost everywhere. CAST increases harmful refusal while mostly preserving harmless compliance.
The result is not that CAST is a complete safety system. The result is narrower and more mechanistic:
A condition vector can gate a behavior vector in hidden-state space.
That is a useful primitive.
6. CAST Properties: Duality, Modulation, and Saturation
The paper discusses three properties that make CAST more programmable than simple steering.
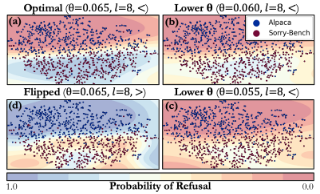
6.1 Duality
If a condition vector represents a category, flipping the comparison direction lets us intervene on the complement set.
For example:
1
if harmful then refuse
can become:
1
if not harmful then refuse
This may sound odd for general refusal, but it is useful for specialized assistants. For example, a health assistant could be programmed as:
1
if not health-related then refuse
This is more scalable than explicitly listing every non-health category.
6.2 Modulation
The threshold $\theta$ controls the trigger boundary. Changing $\theta$ changes how sensitive the condition check is.
This matters because refusal policies are rarely binary in practice. Some domains may need a conservative trigger. Other domains may need a narrower trigger to avoid over-refusal.
6.3 Saturation
CAST depends on representations that already exist inside the model. If a concept is already well represented, CAST can reach strong performance quickly. If the model does not clearly encode the target concept, or if the examples do not capture it well, the method has less to work with.
In other words, CAST does not create a new capability from nothing. It uses the geometry of existing hidden states.
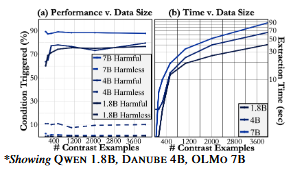
7. Programmed Refusal Through Logical Composition
The most interesting part of CAST is the move from one condition to multiple conditions.
Instead of a single harmfulness condition, the paper constructs category-specific condition vectors:
| Condition vector | Target category |
|---|---|
| $c_{\mathrm{sex}}$ | sexual content |
| $c_{\mathrm{legal}}$ | legal opinions |
| $c_{\mathrm{hate}}$ | hate speech |
| $c_{\mathrm{crime}}$ | crime planning |
| $c_{\mathrm{health}}$ | health consultation |
Then these vectors can be logically composed.
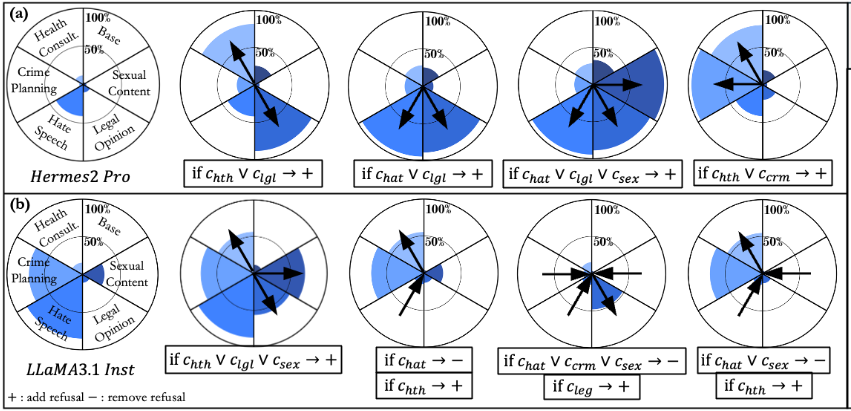
For example:
1
if hate speech or legal opinion then add refusal
can be implemented as:
\[\text{if } c_{\mathrm{hate}} \lor c_{\mathrm{legal}} \text{ then } +v_{\mathrm{refusal}}\]This is why the title uses the word programming. The authors are not merely steering toward a behavior. They are composing small hidden-state conditions into rules.
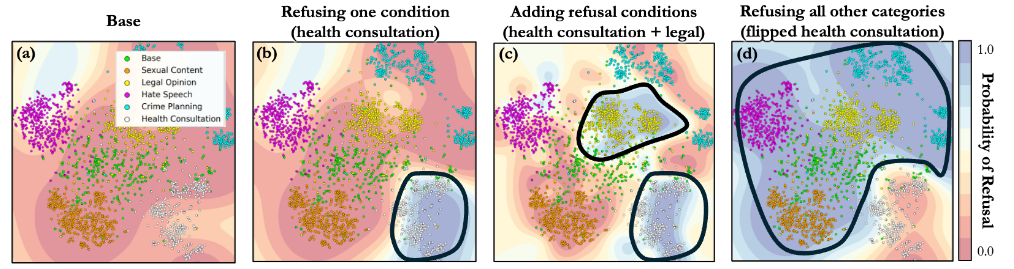
8. Domain-Constrained Assistants
CAST can also be used in the opposite direction: instead of refusing one target category, it can constrain a model to only answer inside one target category.
The health assistant example is:
- Create a health condition vector $c_{\mathrm{health}}$.
- Flip the comparison direction.
- Apply refusal to the complement set.
1
if not health-related then add refusal
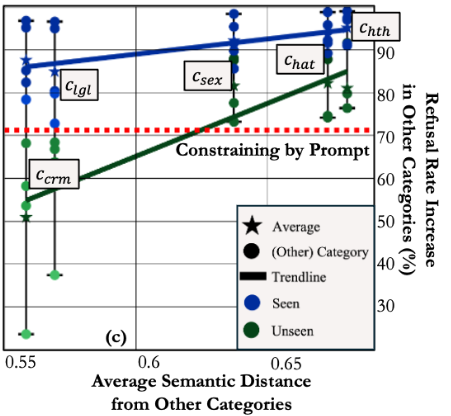
The slide summary also notes an important empirical trend:
Domain restriction works better when the target category is semantically distinct from the other categories.
That makes sense. If two categories are close in representation space, the condition boundary is harder to draw. If they are far apart, a condition vector has a cleaner separation to exploit.
9. Why CAST Is Important
I think CAST is important for three reasons.
First, it addresses a real weakness of activation steering. Simple steering is often too blunt. CAST adds a condition check, which makes the intervention more selective.
Second, it gives a useful mental model for LLM behavior control. Instead of treating model behavior as something that can only be modified by fine-tuning, CAST suggests that some behaviors can be controlled by runtime operations over hidden states.
Third, it connects safety and interpretability. The method assumes that prompt categories correspond to activation patterns. If that assumption holds, then model internals become a surface for safety interventions.
This does not replace alignment training, policy design, red-teaming, or external safety filters. But it provides another layer of control.
10. Limitations and Open Questions
CAST is not a plug-and-play solution for every deployment setting.
The first limitation is access. CAST requires intervention on hidden states. That is natural for open-weight models or research settings, but difficult for closed API models unless the provider exposes an activation-control interface.
The second limitation is robustness. The condition check is based on hidden-state similarity. An adversarial prompt may try to move the activation away from the trigger region while still requesting harmful content. This makes prompt injection and jailbreak robustness important evaluation targets.
The third limitation is search cost. CAST avoids weight optimization, but it still requires:
- contrastive data,
- vector extraction,
- layer selection,
- threshold selection,
- comparison-direction selection,
- behavioral evaluation.
This is much cheaper than full fine-tuning, but it is not zero effort.
Finally, CAST depends on the model’s existing representations. If the model does not encode the target category cleanly, a condition vector may not provide reliable control.
11. Takeaway
The key contribution of CAST is simple:
Steering should not always mean “add this vector everywhere.” It can mean “add this vector only when the hidden state satisfies this condition.”
That makes activation steering much closer to programmable behavior control.
For refusal, the result is selective refusal:
1
2
3
4
refuse harmful prompts
comply with harmless prompts
compose multiple refusal conditions
constrain a model to a target domain
From a safety perspective, CAST is useful because it gives us a way to reduce over-refusal while still increasing refusal on targeted harmful content. From an interpretability perspective, it is useful because it treats hidden-state geometry as something we can inspect, test, and use.
My main remaining question is robustness:
If the condition vector is the trigger, how easily can a jailbreak prompt manipulate the hidden state so that the trigger does not fire?
That question does not weaken the paper. It points to the next layer of evaluation needed before a CAST-style method can be used as a reliable safety mechanism.